“복잡한 Zabbix 운영을 더 효율적으로 만들고 싶다면,
블로그의 핵심 내용을 집대성한 『Zabbix 엔터프라이즈 최적화 핸드북(PDF)』을 확인해보세요.”
https://jikimy.gumroad.com/l/zabbix-master
🧭 관련 글을 찾고 있다면, 검색창에 “모니터링 지표에 대한 고찰” 을 입력해 보세요.
운영 환경에서 MySQL은 단순한 관계형 데이터베이스를 넘어, 수많은 애플리케이션의 핵심 저장소이자 서비스 안정성의 근간을 이룬다.
따라서 MySQL 서버와 쿼리 처리 상태를 세밀하게 모니터링하는 것은 장애 예방과 성능 최적화에 있어 필수적이다.
Zabbix로 읽는 MySQL 성능:
(요약)
- 주기적인 스파이크가(그래프 튀는 현상) 여러 패널에서 같은 시각에 찍히면,
대부분 배치/크론/리포트 쿼리다. 스파이크 높이보다 폭과 지속시간이 중요. - Threads connected, DML, Network가 같이 튀면 애플리케이션 레벨 부하 가능성이 높다.
- Row lock waits와 Disk tmp tables가 함께 오르면 정렬/그룹핑 미인덱스 + 쓰기 경합을 의심.
- Buffer pool hit ratio는 반드시 99%+가 정상. 99% 미만이면 즉시 원인 분석.
1) InnoDB 현재 열린 파일 수
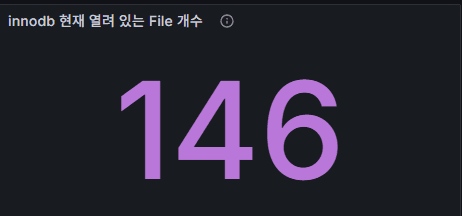
의미: InnoDB가 오픈한 파일 핸들 수(테이블스페이스 등).
정상 범위: 보통 수십~수백. innodb_open_files 한도 내면 OK.
문제 신호: 갑자기 급증하며 에러가 동반 → 파일 핸들 제한/OS ulimit 확인.
체크
SHOW VARIABLES LIKE 'innodb_open_files';
SHOW ENGINE INNODB STATUS\G
2) 커넥션 현황 (Aborted/Connections per sec 등)
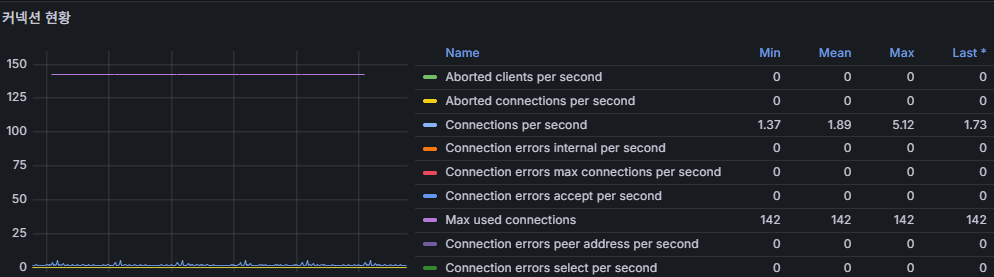
의미
- Aborted clients / Aborted connects: 연결 중단(클라이언트가 소켓을 닫음) / 연결 실패(권한, 네트워크, 타임아웃).
- Connections per second: 초당 신규 연결. 풀링이 있으면 완만, 없으면 톱니처럼 튐.
정상/경고 기준(권장)
Aborted connects가 연속 증가(예: 5분 동안 분당 5~10 이상) → 자격증명/권한/네트워크/방화벽/timeout 점검.Connections/s가 평소 대비 3배↑, 그리고Threads_connected도 같이 상승 → 풀 미스/스파이크 부하.
실무 팁
- 풀링(서버/ORM) 사용 여부 재확인.
wait_timeout,interactive_timeout과도하면 커넥션 낭비.
빠른 확인 SQL
SHOW GLOBAL STATUS LIKE 'Aborted%';
SHOW GLOBAL STATUS LIKE 'Threads_connected';
3) 쿼리 현황 (Queries/s vs Questions/s)
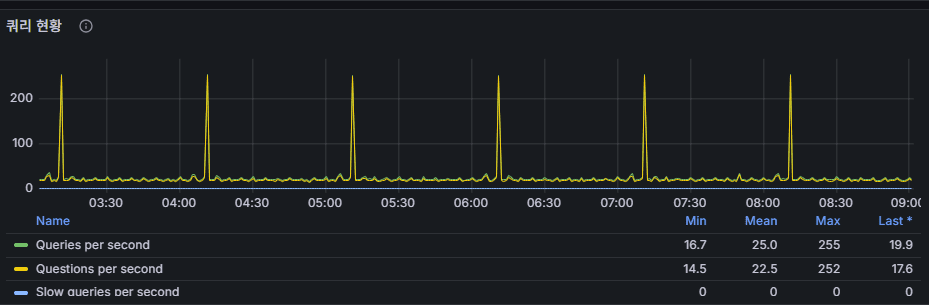
의미
- Queries와 Questions는 MySQL 버전/정의에 따라 약간 다르게 증가한다. 대체로 초당 실행 명령 수로 보면 된다.
- 스크린샷처럼 규칙적 피크는 배치성 쿼리 신호
- slow query 없음
문제 신호
- 피크 때만 느리면 → 배치 쿼리 튜닝/스케줄 분산.
- 상시 높은데 레이턴시/락이 동반 → 인덱스/쿼리 플랜/스키마 점검.
튜닝 포인트
- 빈번한
ORDER BY/GROUP BY열에 적정 인덱스. - 불필요한 SELECT N+1 패턴 제거.
4) MySQL network 트래픽 (Bytes sent/received)
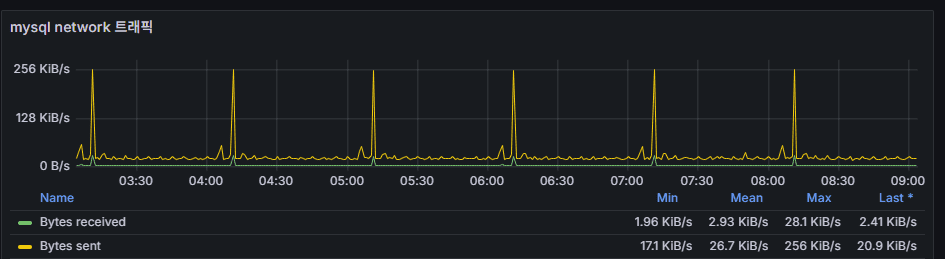
의미: DB-애플리케이션간 I/O 양상. DML/SELECT 피크와 보조지표.
패턴 읽기: DML/Queries 스파이크와 동시에 튀면 정상적 상관관계.
문제 신호: 네트워크만 급증, 쿼리는 평시 → 대량 덤프/백업/복제/툴 헬스체크 확인.
5) InnoDB Buffer Pool 사용률 & Cache hit 비율
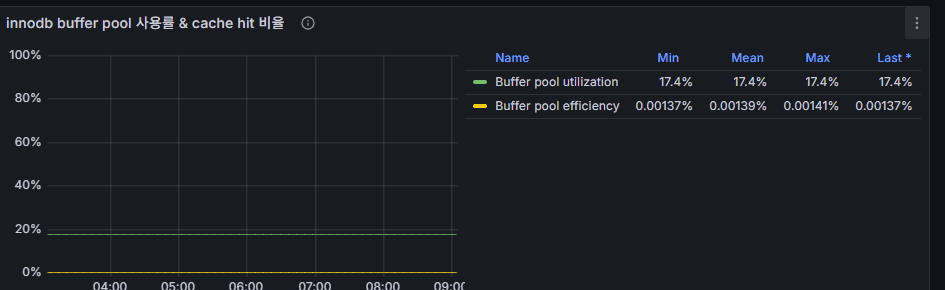
의미
- Buffer Pool Utilization: 버퍼 풀(메모리) 중 사용 중인 비율.
- Buffer Pool Hit Ratio: 디스크 대신 메모리 적중률. 99%+가 일반적으로 정상.
대시보드 지표 관찰 포인트
- **사용률이 약 12~13%**로 낮다 → 버퍼 풀이 워킹셋보다 크다는 뜻일 수 있다(나쁜 건 아님, 메모리 여유 확인 후 유지/축소 판단).
- Hit 비율이 0.03%대처럼 보이는 표시 오류: 실제로는 99% 이상이어야 정상.
- zabbix 홈페이지에 mysql by agnet2 템플릿의 해당 지표값 설명에 따르면
히트율로 오해하기 쉬우나 zabbix item 수식값을 보면 미스율(miss %)로 보는게
맞을 듯 하다. – 수치가 낮을수록 좋음
grafana에서 관련 지표값 제목을 미스율로 변경하거나 hit율로 유지하고자 한다면 zabbix item 수식값을 변경하면 된다.
- zabbix 홈페이지에 mysql by agnet2 템플릿의 해당 지표값 설명에 따르면
교정 전 [미스율(miss rate) 수식]
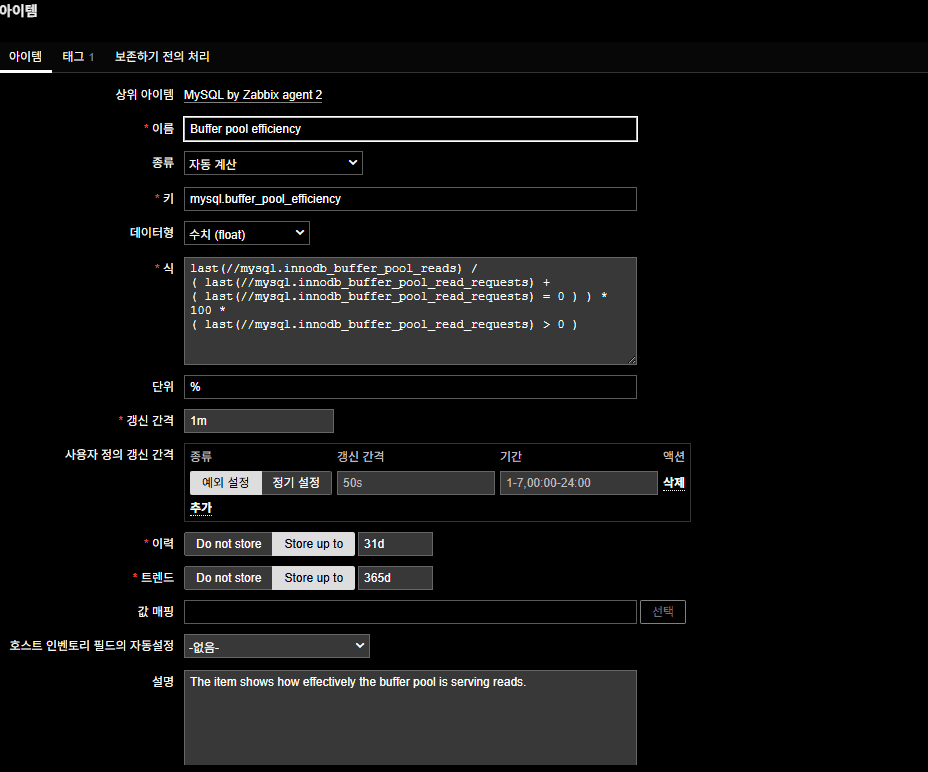
교정 가이드(그래프 수식)
- 올바른 계산:
100 * ( 1 -last(//mysql.innodb_buffer_pool_reads)/( last(//mysql.innodb_buffer_pool_read_requests)+ ( last(//mysql.innodb_buffer_pool_read_requests) = 0 ) ))
문제 신호
- Hit%가 99% 미만으로 유지 → 버퍼 풀 확장(메모리 허용 시) + 핫셋 인덱싱 확인.
확인 SQL
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool_read%';
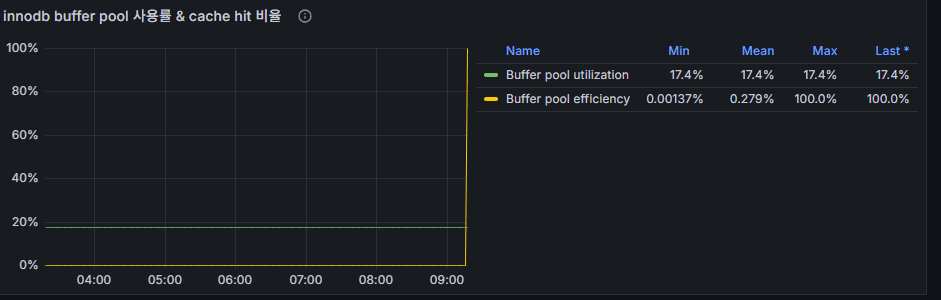
- 수식 변경후 적용된 hit율 지표 이미지
6) 초당 DML 횟수 (Insert/Update/Delete/Select)
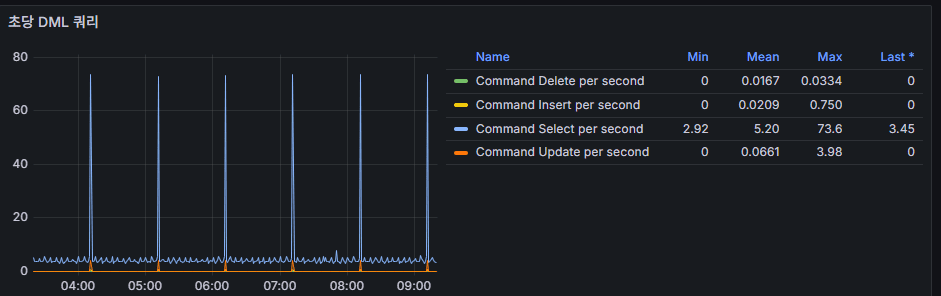
의미: 작업 유형별 쓰기/읽기 부하.
읽는 법: 정각/30분 등 규칙 스파이크 → 스케줄 잡.
문제 신호: Update/Delete가 짧은 시간에 높은 피크 + Row lock waits 동반 → 테이블/레코드 경합.
튜닝 포인트
- 잦은 Update 대상 컬럼/조건에 인덱스 재검토.
- 대량 수정은 작게 나눠 배치(트랜잭션 시간 축소).
- 파티셔닝/샤딩 고려.
7) 현재 커넥션 개수 (Threads_connected)
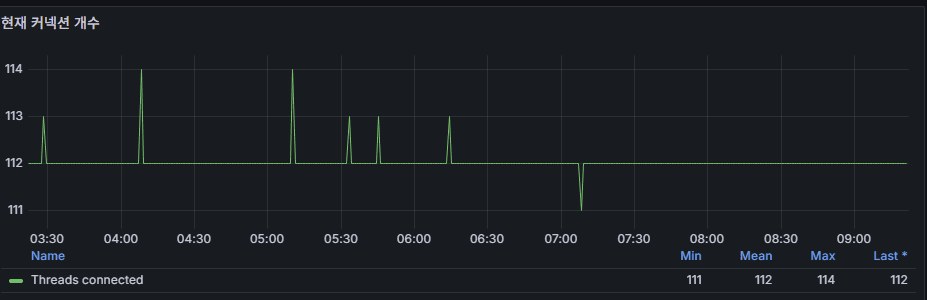
의미: 현재 열린 커넥션 수.
스샷 특징: 평소 111~114 수준으로 보임 → 풀 크기와 유사해 보인다(지속 유지형 커넥션).
문제 신호
Threads_connected / max_connections > 0.8가 5분 이상 → 커넥션 고갈 위험.max_used_connections가max_connections에 자주 근접 → 풀/쿼리/타임아웃 점검.
확인 SQL
SHOW VARIABLES LIKE 'max_connections';
SHOW GLOBAL STATUS LIKE 'Max_used_connections';
8) ROW 잠금 Wait 발생 건수 (InnoDB row lock waits)
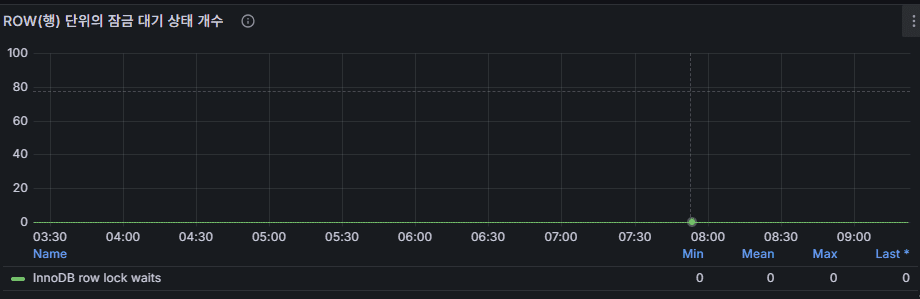
의미: 레코드 잠금 대기 발생량.
좋은 상태: 0에 가깝거나 드물게 발생.
문제 신호: DML 스파이크와 동시에 급증 → 동일 키/범위 경합.
대응
- 충돌 키에 적절한 인덱스.
- 긴 트랜잭션 쪼개기.
- 필요 시 격리수준 조정(READ COMMITTED 등) 검토.
- 충돌 쿼리 식별: Performance Schema 사용.
SELECT * FROM performance_schema.data_locks\G
9) 초당 생성되는 임시 테이블 수 (특히 “디스크” 임시 테이블)
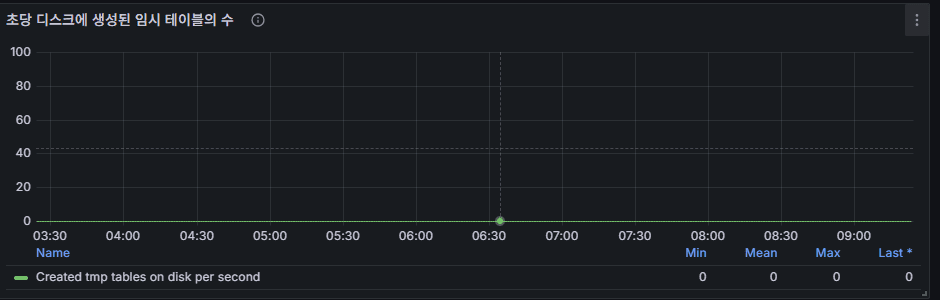
의미: 쿼리 정렬/그룹핑/조인 시 메모리 임시 테이블로 감당 못하면 디스크 임시 테이블이 생김.
스샷: 주기적 스파이크(10개 내외) → 배치성 정렬/집계가 있는 듯.
문제 신호
- 디스크 임시 테이블 생성이 상시 높음(초당 수십~수백) → 느려짐/IO 증가.
튜닝 포인트
tmp_table_size와max_heap_table_size를 동일 높이로 확대(메모리 상황 봐서).GROUP BY/ORDER BY컬럼 인덱스 설계.- TEXT/BLOB이 임시 테이블로 넘어가면 디스크 사용 확률↑ → 스키마/쿼리 재설계.
확인 SQL
SHOW GLOBAL STATUS LIKE 'Created_tmp%';
SHOW VARIABLES LIKE 'tmp_table_size';
SHOW VARIABLES LIKE 'max_heap_table_size';
10) “디스크에 생성된 임시 파일/테이블” 추가 지표
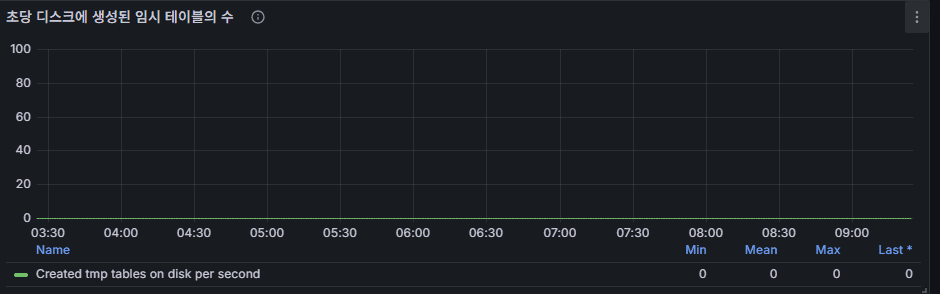
의미: 위와 같은 맥락의 보조 지표.
읽는 법: DML/Queries 스파이크와 같이 튀면 SELECT 정렬/집계가 원인.
대응: 위의 임시 테이블 파트와 동일하게 접근.
이상 징후가 보이면:
점검 루틴
- 같이 튀는 패널이 무엇인지 먼저 본다
- DML↑, Network↑, Threads_connected↑ → 앱 부하 스파이크.
- Disk tmp tables↑, Row lock waits↑ → 인덱스/쿼리 설계 문제.
- 가해자 쿼리 찾기
-- 상위 비용 쿼리(요약)
SELECT DIGEST_TEXT, COUNT_STAR, SUM_TIMER_WAIT, SUM_LOCK_TIME
FROM performance_schema.events_statements_summary_by_digest
ORDER BY SUM_TIMER_WAIT DESC
LIMIT 20;
- 슬로우로그를 확인
- 상황에 맞게 인덱스/파라미터 튜닝
Zabbix 트리거(예시 가이드라인)
템플릿의 기본적인 트리거와 함께 아래 예시를 참조해서 지표값에 대한 트리거를
운영상황에 맞게 수치 조정
- Buffer pool hit < 99% for 5m → Warning
- Threads_connected / max_connections > 0.8 for 5m → High
- Created tmp tables on disk/s > 50 for 5m → Warning
- Row lock waits/s > 0 for 5m → Warning
- Aborted connects 증가 속도↑ (5m 이동평균 > 임계) → Warning
* 중요 포인트
개인적으로 대용량 트래픽 사이트에서는
innodb buffer 사용률과 함께 DISK IO 지표를 중요 포인트로 관찰하는 편임 :
mysql은 in-memory db가 아니고 innodb buffer 에 할당된 메모리 영역에
cache 역할로서의 data만 메모리에 반영하는 부분이기 때문에
disk io가 늘어나는 순간 그 DB는 무조건 튜닝해야 함.
아울러 dirty page(cache된 메모리 영역 data에 업데이트가 일어난 data) 가
생기면,
disk에 반영을 해야 하는데 이 행동을 flush라고 하고, 이러한 지표값들 역시
disk io가 늘어나는데 한 몫을 하기 때문에 DB 성능에 중요한 모니터링 대상임
🛠 마지막 수정일: 2025.12.22
ⓒ 2025 엉뚱한 녀석의 블로그 [quirky guy's Blog]. All rights reserved. Unauthorized copying or redistribution of the text and images is prohibited. When sharing, please include the original source link.
💡 도움이 필요하신가요?
Zabbix, Kubernetes, 그리고 다양한 오픈소스 인프라 환경에 대한 구축, 운영, 최적화, 장애 분석,
광고 및 협업 제안이 필요하다면 언제든 편하게 연락 주세요.
📧 Contact: jikimy75@gmail.com
💼 Service: 구축 대행 | 성능 튜닝 | 장애 분석 컨설팅
📖 E-BooK [PDF] 전자책 (Gumroad):
Zabbix 엔터프라이즈 최적화 핸드북
블로그에서 다룬 Zabbix 관련 글들을 기반으로 실무 중심의 지침서로 재구성했습니다.
운영 환경에서 바로 적용할 수 있는 최적화·트러블슈팅 노하우까지 모두 포함되어 있습니다.
💡 Need Professional Support?
If you need deployment, optimization, or troubleshooting support for Zabbix, Kubernetes,
or any other open-source infrastructure in your production environment, or if you are interested in
sponsorships, ads, or technical collaboration, feel free to contact me anytime.
📧 Email: jikimy75@gmail.com
💼 Services: Deployment Support | Performance Tuning | Incident Analysis Consulting
📖 PDF eBook (Gumroad):
Zabbix Enterprise Optimization Handbook
A single, production-ready PDF that compiles my in-depth Zabbix and Kubernetes monitoring guides.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.