運用環境における MySQL は、単なるリレーショナルデータベースにとどまらず、
多数のアプリケーションにとって中核的な永続ストアであり、サービス安定性の基盤そのものだ。
したがって、MySQL サーバーおよびクエリ処理状態を細かく監視することは、障害予防や性能最適化に欠かせない。
Zabbix で読む MySQL パフォーマンス
(要約)
- 複数のパネルで同一時刻にスパイクが発生する場合、ほとんどは バッチ/Cron/レポート系クエリ。
スパイクの高さよりも、幅(持続時間)が重要。 - Threads connected・DML・Network が同時に跳ねる場合、アプリケーションレイヤの負荷である可能性が高い。
- Row lock waits + Disk tmp tables が同時に増える場合、インデックス不足+書き込み競合を疑う。
- Buffer pool hit ratio は必ず 99%以上が正常値。
99%未満なら即原因分析が必要。
1) InnoDB が現在開いているファイル数
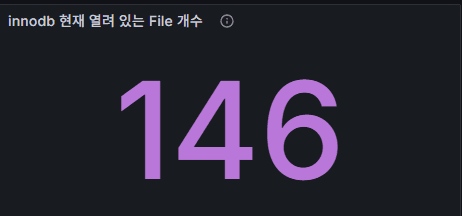
意味:InnoDB がオープンしているファイルハンドル数(テーブルスペースなど)。
正常範囲:数十〜数百程度。innodb_open_files の上限内なら問題なし。
異常の兆候:急増 + エラー発生 → OS のファイルハンドル制限/ulimit を確認。
チェック
SHOW VARIABLES LIKE 'innodb_open_files';
SHOW ENGINE INNODB STATUS\G
2) 接続状況(Aborted / Connections per sec など)
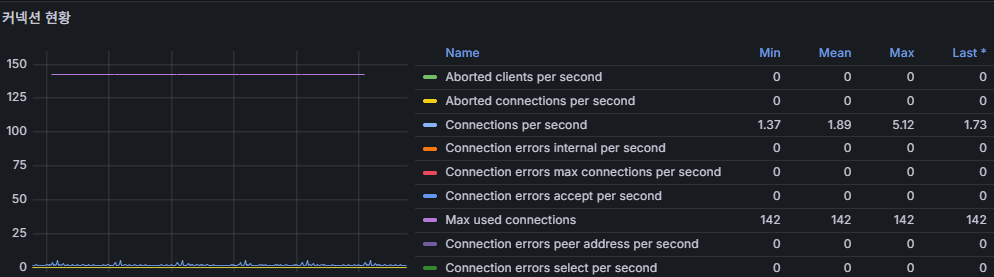
意味
- Aborted clients / Aborted connects:
クライアント側でソケットが閉じられた/接続失敗(権限・ネットワーク・Timeout 等)。 - Connections per second:1 秒あたりの新規接続数。
コネクションプールがあれば緩やか、無ければギザギザの波形になりやすい。
判断基準(推奨)
- Aborted connects が継続的に増加
(例:5 分間で毎分 5〜10 以上)
→ 権限・資格情報・ネットワーク・FW・Timeout を点検。 - Connections/s が平常比 3 倍 + Threads_connected も増加
→ プールミス or スパイク負荷。
実務的ポイント
- アプリ/ORM の接続プールの有無を再確認。
wait_timeout/interactive_timeoutが過剰だと接続浪費が起こる。
クイック確認
SHOW GLOBAL STATUS LIKE 'Aborted%';
SHOW GLOBAL STATUS LIKE 'Threads_connected';
3) クエリ状況(Queries/s vs Questions/s)
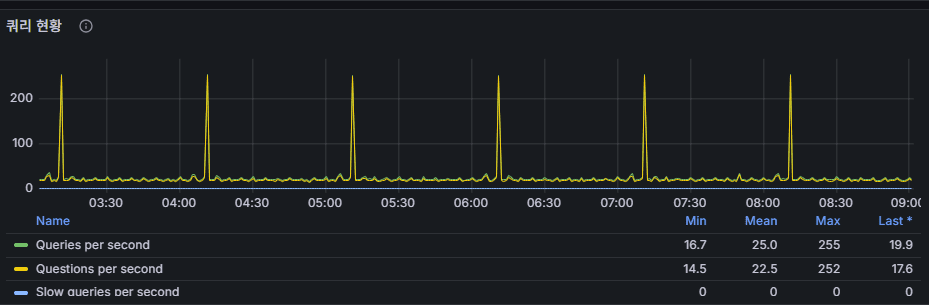
意味
MySQL バージョンにより微妙に定義が異なるが、概ね「実行された命令数/秒」と見てよい。
パターン読み取り
- スクリーンショットのように 規則的なピーク → バッチ系クエリの典型サイン
- slow query がない場合は特に顕著。
問題シグナル
- ピーク時だけ遅い → バッチのチューニングまたはスケジュール分散。
- 常時高い + レイテンシ/ロック増加 → インデックス/実行計画/スキーマ点検。
チューニング
- ORDER BY / GROUP BY 列に適切なインデックスを付与。
- N+1 SELECT を排除。
4) MySQL ネットワークトラフィック(Bytes sent/received)
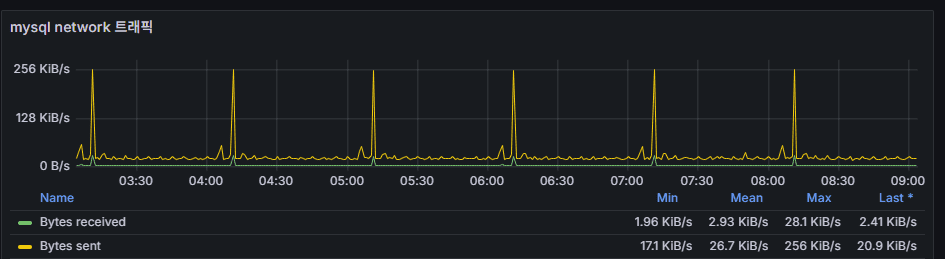
意味:DB とアプリ間 I/O の量。DML/SELECT の補助指標。
自然な相関:DML・Queries のスパイクと同時に増える。
異常:ネットワークだけ急増 → ダンプ/バックアップ/レプリケーション/ヘルスチェックツール等を確認。
5) InnoDB Buffer Pool 使用率 & Cache Hit 比率
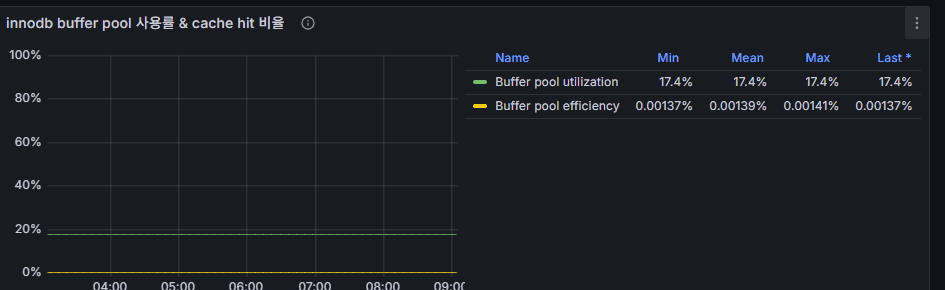
意味
- Buffer Pool Utilization:バッファプールの使用割合。
- Hit Ratio:ディスクではなくメモリにヒットした確率。正常値は 99%+。
観察ポイント
- 使用率が 12〜13% と低い場合 → 作業セットよりバッファプールが大きい可能性(悪くはない)。
- Hit 比率が 0.03% などに見えるのは 表示誤差の場合がある。実際は 99% 以上が正常。
Zabbix テンプレート説明では Hit 率のように読めるが、
Item の数式を見ると “Miss 率(低いほど良い)” になっている。
- Grafana ではタイトルを “Miss 率” に変更すると分かりやすい。
- Hit 率で表示したい場合は Zabbix 側の Item 数式を修正する。
修正前 [Miss Rate の数式]
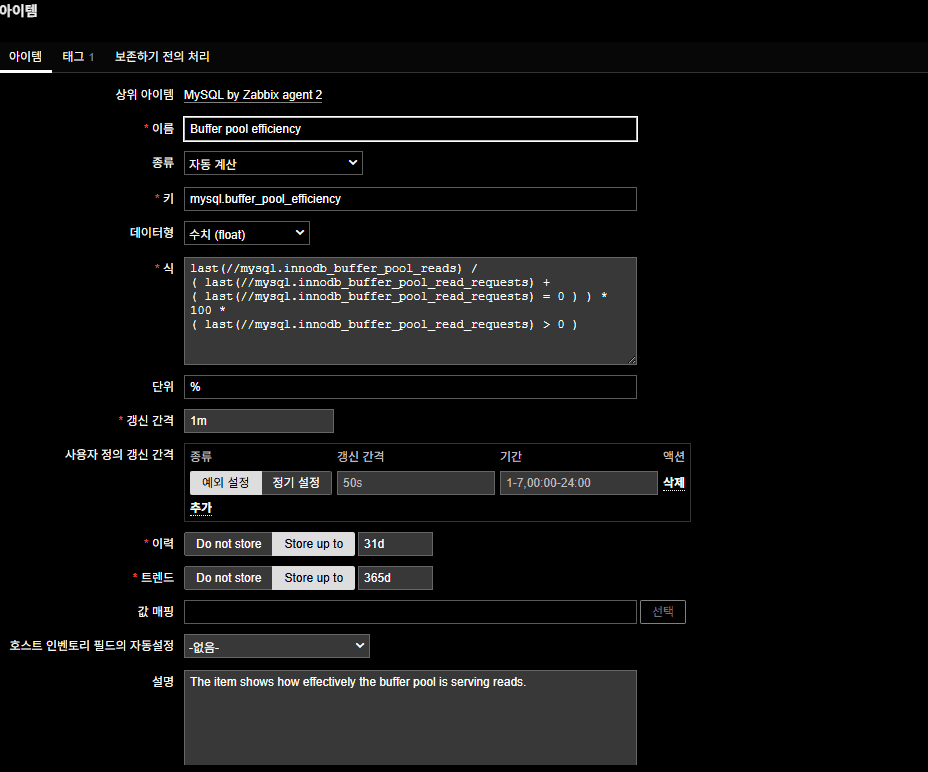
正しい Hit 率計算式
100 * ( 1 -
last(//mysql.innodb_buffer_pool_reads) /
( last(//mysql.innodb_buffer_pool_read_requests)
+ (last(//mysql.innodb_buffer_pool_read_requests) = 0) )
)
問題シグナル
- Hit% が 99% 未満で維持 → バッファプール拡張 + ホットセットのインデックス確認。
確認
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool_read%';
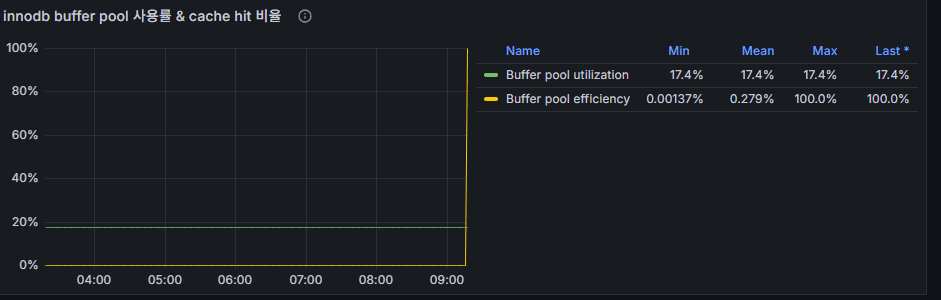
数式変更後に適用された Hit 率指標の画像
6) DML 回数/秒(Insert/Update/Delete/Select)
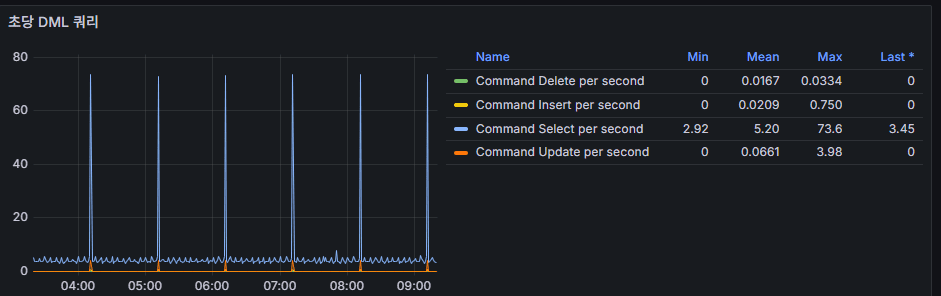
意味:書き込み/読み込み負荷の種類。
読み方
- 正時刻/30 分刻みでスパイク → バッチジョブ。
- Update/Delete が短時間で高いピーク + Row lock waits → 競合疑い。
チューニング
- 頻繁に更新される列・条件のインデックス再検討。
- 大量更新は小分けにしてトランザクション時間を短縮。
- 場合によりパーティショニング/シャーディング。
7) 現在の接続数(Threads_connected)
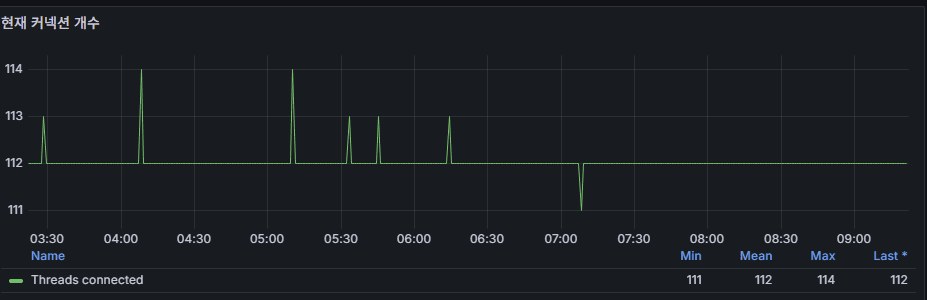
意味:現在開いている接続数。
観察例
- 111〜114 程度 → コネクションプールのサイズとほぼ一致。
問題シグナル
Threads_connected / max_connections > 0.8が 5 分以上 → 接続枯渇リスク。max_used_connectionsが上限に接近し続ける → プール・クエリ・Timeout 再検討。
確認
SHOW VARIABLES LIKE 'max_connections';
SHOW GLOBAL STATUS LIKE 'Max_used_connections';
8) ROW Lock Wait(InnoDB row lock waits)
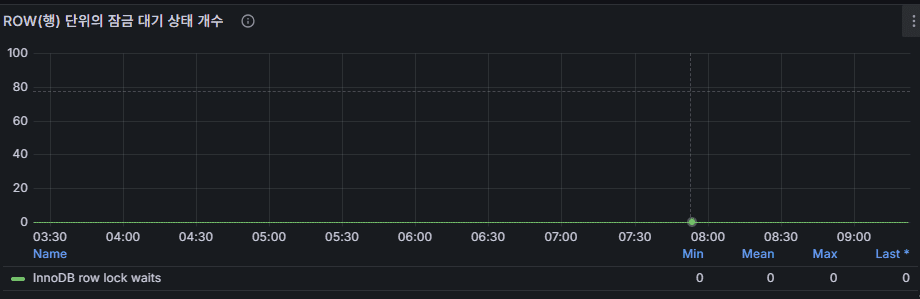
意味:レコードロック待ち。
正常:ほぼ 0。
問題:DML スパイクと同時に急増 → 同一キー/範囲の競合。
対応
- 競合キーに適切なインデックス。
- 長いトランザクションを分割。
- 必要に応じて隔離レベル READ COMMITTED を検討。
問題クエリ確認
SELECT * FROM performance_schema.data_locks\G
9) 一時テーブル生成数(特に DISK temporary tables)
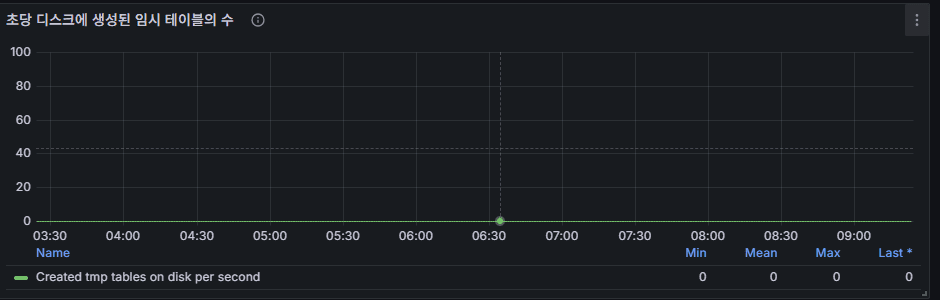
意味:ソート/グループ/結合時、メモリで収まらない場合はディスク利用。
観察例:周期的スパイク(10 件前後) → バッチの集計・ソート。
問題シグナル
- ディスク一時テーブルが常時高値(秒間数十〜数百) → 遅延/IO 増加。
チューニング
tmp_table_sizeとmax_heap_table_sizeを同一値で適正に拡大。- ORDER BY / GROUP BY にインデックス。
- TEXT/BLOB を含むクエリはディスク利用に寄りやすい → スキーマ/クエリ再検討。
確認
SHOW GLOBAL STATUS LIKE 'Created_tmp%';
SHOW VARIABLES LIKE 'tmp_table_size';
SHOW VARIABLES LIKE 'max_heap_table_size';
10) “ディスクに作成された一時ファイル/テーブル” の追加指標
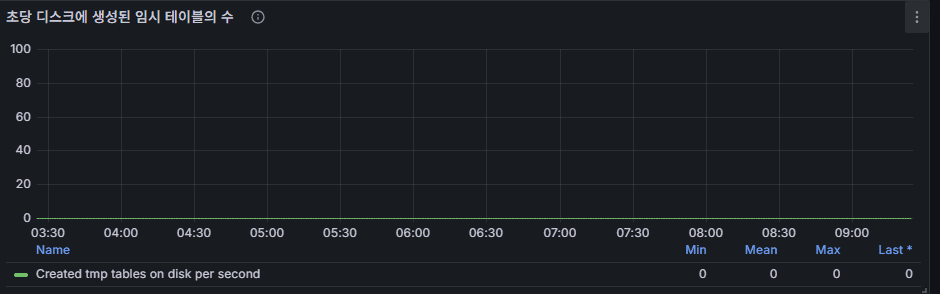
意味:上記の補助指標。
読み方:DML/Queries スパイクと同時 → SELECT のソート/集計が原因。
対応:一時テーブル項目と同じ。
異常が見えたときの診断手順
1) 同時に跳ねているパネルを確認
- DML↑、Network↑、Threads_connected↑ → アプリ負荷スパイク
- Disk tmp tables↑、Row lock waits↑ → インデックス/クエリ設計の問題
2) 加害者クエリを特定
-- コスト上位クエリ(要約)
SELECT DIGEST_TEXT, COUNT_STAR, SUM_TIMER_WAIT, SUM_LOCK_TIME
FROM performance_schema.events_statements_summary_by_digest
ORDER BY SUM_TIMER_WAIT DESC
LIMIT 20;
- slow log を確認
- インデックス/パラメータを状況に応じて調整
Zabbix トリガー例(ガイドライン)
運用環境に合わせて数値を調整。
- Buffer pool hit < 99% が 5 分継続 → Warning
- Threads_connected / max_connections > 0.8 が 5 分継続 → High
- Created tmp tables on disk/s > 50 が 5 分 → Warning
- Row lock waits/s > 0 が 5 分 → Warning
- Aborted connects 増加速度(5 分移動平均 > 閾値) → Warning
重要ポイント
大規模トラフィック環境では、
InnoDB Buffer 使用率と Disk IO の組み合わせが最重要指標。
MySQL はインメモリ DB ではなく、
バッファプールは キャッシュとしてのメモリ領域 にすぎない。
したがって Disk IO が増えた瞬間、その DB はチューニング必須。
また Dirty Page(バッファ内データが更新されたもの)は
フラッシュによりディスクへ反映されるため、
これらの値も Disk IO を増加させ、性能に直結する重要な監視対象となる。
🛠 마지막 수정일: 2025.11.19
💡 お困りですか?
Zabbix、Kubernetes、各種オープンソースインフラの構築・運用・最適化・障害解析が必要であれば、いつでもご連絡ください。
📧 メール: jikimy75@gmail.com
💼 サービス: 導入支援 | 性能チューニング | 障害解析コンサルティング
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.