1. Introduction
In the previous post, we looked at the concept of Split Brain and introduced MySQL HA as a representative example.
In this article, we will expand on that discussion and, based on an actual production environment, explain how to prevent Split Brain using a Pacemaker + Corosync + MySQL Dual Master Replication setup.
This guide is written by recalling a configuration that was successfully operated in the past. Therefore, it should not be applied as-is to modern deployments. Instead, adapt it carefully to fit your own environment.
The installation of MySQL and the setup of replication are well documented elsewhere, so they are omitted here. The focus will be on HA design and failover logic.
It should also be noted that there are many other approaches to MySQL HA, such as InnoDB Cluster, Group Replication, and Galera, and what we describe here is only one of several possible methods.
2. What is Split Brain?
Split Brain occurs when a network partition or health-check error causes both nodes in a cluster to incorrectly believe they are the master.
In database environments, this leads to data inconsistency and corruption, making prevention absolutely critical.
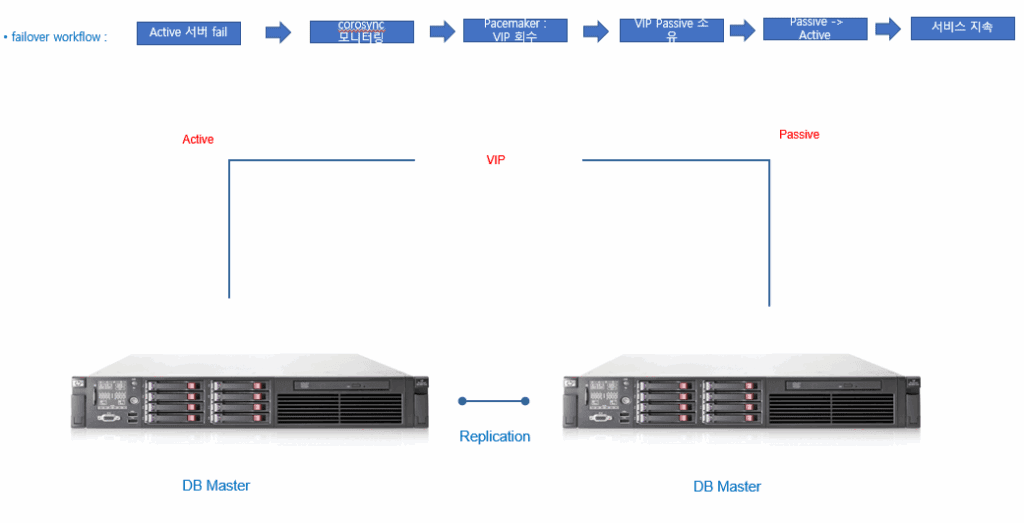
3. Architecture Overview
- MySQL Dual Master Replication
Both nodes are configured as masters in a replication relationship. However, client traffic is always directed to the Active node through a Virtual IP (VIP). - Pacemaker + Corosync
- Pacemaker: Manages resources and handles failover.
- Corosync: Provides cluster communication and quorum management.
- The VIP is assigned only to the Active node and will move to the Passive node in case of failure.
- Failover Workflow
- Active node failure detected
- Corosync monitoring triggers Pacemaker to release the VIP
- VIP is reassigned to the Passive node
- Passive node is promoted to Active
- Service continues uninterrupted
4. Key Concepts
- Quorum
Provides consensus within the cluster. In a two-node setup, quorum alone is insufficient, so network monitoring resources are required to compensate. - STONITH (Fence Device)
- Forces a failed node to be powered off or isolated.
- It is the strongest safeguard against Split Brain, but introduces significant complexity.
- In this guide, Split Brain prevention is achieved primarily through network monitoring, with STONITH considered only as an optional enhancement.
- Network Monitoring Resource
Simple health checks are not enough to detect real network partitions.
By adding anethmonitorresource, the cluster can monitor the actual state of a network interface.
This ensures that short-term glitches are ignored, and only sustained failures trigger failover.
This method was proven stable in production for several years.
5. Installation & Configuration Summary
(MySQL installation and replication setup are omitted.)
Install Pacemaker/pcs : The following configuration examples are based on RHEL distributions (yum install pcs), and Ubuntu/Debian distributions require separate adaptation since the commands and tools differ.
yum install -y pcs
systemctl enable --now pcsd
Cluster Setup
pcs cluster auth DB01 DB02 -u hacluster -p <password>
pcs cluster setup --name mysql_ha DB01 DB02
pcs cluster start --all
Cluster Properties
# Disable STONITH (Split Brain handled by network monitoring)
pcs property set stonith-enabled=false
# Ignore quorum policy (necessary in a 2-node setup)
pcs property set no-quorum-policy=ignore
VIP Resource
pcs resource create mysql_vip ocf:heartbeat:IPaddr2 ip=192.10.10.252 cidr_netmask=32 \
op monitor interval=5s meta migration-threshold=2 failure-timeout=10s
MySQL Service Resource
pcs resource create mysql_service ocf:heartbeat:mysql \
binary="/usr/local/mysql/bin/mysqld_safe" config="/etc/my.cnf" \
datadir="/data/mysql_data" user="mysql" group="mysql" \
pid="/data/mysql_data/mysqld.pid" socket="/tmp/mysql.sock" \
op monitor interval=5s timeout=10s on-fail=standby
pcs resource clone mysql_service clone-max=2 clone-node-max=1
Network Monitoring Resource
# ethmonitor: monitors the state of a specified NIC
# - interface: the network interface to monitor
# - interval: how frequently to check
# - timeout: failure threshold before action
# - on-fail: standby the node if monitoring fails
pcs resource create network_monitor ocf:heartbeat:ethmonitor interface=eno8 \
op monitor interval=2s timeout=5s on-fail=standby
# Ensure VIP and network monitoring always move together
pcs constraint colocation add network_monitor with mysql_vip INFINITY
pcs constraint order network_monitor then mysql_vip
6. Operational Notes
- The VIP must only ever run on a single node, preserving the Active/Passive design.
- Failover should only occur after a sustained outage, not during momentary network hiccups.
- Network monitoring replaces the need for STONITH in this setup.
- This approach was validated and operated successfully in production.
7. Conclusion
This post builds on the previous discussion of Split Brain and presents a practical, proven configuration using Pacemaker + Corosync + MySQL Dual Master Replication.
In modern deployments, always adapt the setup to your environment, and refer to the official MySQL documentation for installation and replication details.
The key is to use a VIP in combination with network monitoring resources to ensure that two nodes never serve traffic simultaneously.
STONITH remains an optional safeguard; this configuration alone is sufficient to prevent Split Brain in practice.
Furthermore, high availability should not rely solely on cluster logic.
While Pacemaker and Corosync handle failover, integrating an external monitoring system adds resilience.
Tools like Zabbix or Prometheus can provide early detection of issues such as VIP transitions, replication lag, or network partitions.
By layering proactive monitoring on top of the cluster, you move beyond simple recovery and significantly increase overall service reliability.
🛠 마지막 수정일: 2025.09.19
ⓒ 2025 엉뚱한 녀석의 블로그 [quirky guy's Blog]. All rights reserved. Unauthorized copying or redistribution of the text and images is prohibited. When sharing, please include the original source link.
💡 도움이 필요하신가요?
Zabbix, Kubernetes, 그리고 다양한 오픈소스 인프라 환경에 대한 구축, 운영, 최적화, 장애 분석,
광고 및 협업 제안이 필요하다면 언제든 편하게 연락 주세요.
📧 Contact: jikimy75@gmail.com
💼 Service: 구축 대행 | 성능 튜닝 | 장애 분석 컨설팅
📖 E-BooK [PDF] 전자책 (Gumroad):
Zabbix 엔터프라이즈 최적화 핸드북
블로그에서 다룬 Zabbix 관련 글들을 기반으로 실무 중심의 지침서로 재구성했습니다.
운영 환경에서 바로 적용할 수 있는 최적화·트러블슈팅 노하우까지 모두 포함되어 있습니다.
💡 Need Professional Support?
If you need deployment, optimization, or troubleshooting support for Zabbix, Kubernetes,
or any other open-source infrastructure in your production environment, or if you are interested in
sponsorships, ads, or technical collaboration, feel free to contact me anytime.
📧 Email: jikimy75@gmail.com
💼 Services: Deployment Support | Performance Tuning | Incident Analysis Consulting
📖 PDF eBook (Gumroad):
Zabbix Enterprise Optimization Handbook
A single, production-ready PDF that compiles my in-depth Zabbix and Kubernetes monitoring guides.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.