50-node ML Kubernetes Cluster 설계 사례
이 문서는 CPU와 GPU 노드가 혼합된 On-Prem 환경에서 ML 워크로드를 위한 Kubernetes Cluster를 어떻게 설계해야 하는지 설명한다.
핵심 목표는 GPU 자원의 효율적 활용과 고성능 I/O를 위한 스토리지 계층화다.
1. 전체 구조 개요
클러스터는 총 50노드( GPU 15대 + CPU 35대 )로 구성된다.
GPU 노드는 주로 학습(Training), CPU 노드는 전처리, 데이터 적재, 서빙(Serving)용으로 사용된다.
아래는 전체 아키텍처 개념도다.
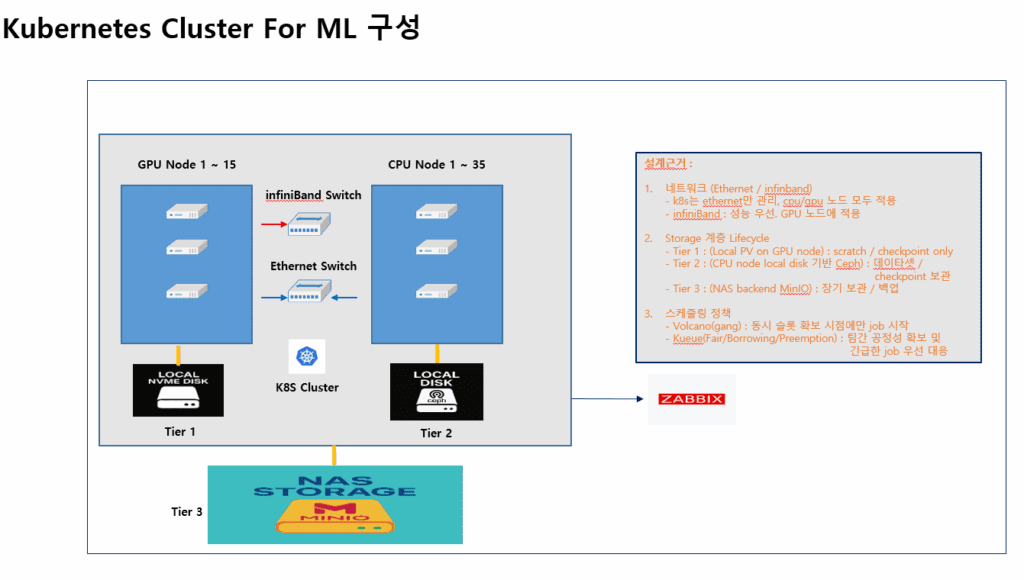
GPU Node 1~15 → NVMe 기반 Tier1 Local Disk
CPU Node 1~35 → Ceph 기반 Tier2 Local Disk
NAS (MinIO) → Tier3 백업/장기보관 스토리지
네트워크는 InfiniBand + Ethernet 병행 구성
2. 네트워크 설계 (Ethernet + InfiniBand)
2.1 구조
- Ethernet Switch
- 모든 노드에 공통 적용.
- Kubernetes 클러스터 내부 통신 (Control Plane, API, Pod 네트워킹) 담당.
- InfiniBand Switch
- GPU 노드에만 적용.
- 모델 학습 중 GPU 간 파라미터 동기화(AllReduce, NCCL 통신 등)에 고성능 RDMA 링크 제공.
2.2 적용 정책
k8s는 Ethernet 네트워크만 관리한다. (CNI: Cilium or Calico)- InfiniBand는 Kubernetes 외부 네트워크로 설정, Pod 내에서 직접 사용하도록 구성한다.
- GPU 노드만 InfiniBand NIC를 활성화하여 고속 GPU to GPU 통신을 전용 경로로 분리.
이렇게 하면 CPU 노드의 불필요한 비용을 줄이면서 GPU 클러스터의 통신 병목을 해소할 수 있다.
3. Storage 계층 구조
머신러닝 워크로드는 학습 데이터셋, 체크포인트, 모델 결과물 등 다양한 스토리지 요구사항이 있다.
따라서 스토리지를 3계층으로 구분했다.
| Tier | 구성 | 목적 | 비고 |
|---|---|---|---|
| Tier 1 | GPU Node의 Local NVMe Disk | Scratch / Checkpoint Only | 초고속 임시 저장용, Pod Local PV로 구성 |
| Tier 2 | CPU Node Local Disk 기반 Ceph | Dataset / Checkpoint 저장 | Ceph RBD or CephFS 사용 |
| Tier 3 | NAS (MinIO backend) | 장기 보관 / 백업 | Object Storage, S3 API 호환 |
3.1 Tier 1 — Local NVMe
- 각 GPU 노드의 로컬 NVMe SSD를 Local Persistent Volume으로 사용.
- 모델 학습 중 intermediate file, temporary checkpoint 보관.
- Pod 종료 시 삭제 정책(
delete)으로 관리, 속도 최우선.
3.2 Tier 2 — Ceph Cluster
- CPU 노드의 로컬 디스크를 묶어 Ceph Storage 구성.
- 주요 데이터셋 및 학습 중간 결과를 중앙집중형으로 관리.
- GPU 노드에서도 Ceph Volume을 마운트하여 공유 데이터 접근 가능.
3.3 Tier 3 — MinIO NAS
- MinIO 기반 NAS Object Storage를 Tier3로 구성.
- 장기 보관용으로 사용하며, Ceph 데이터의 백업 대상.
mc mirror혹은rclone으로 Ceph ↔ MinIO 간 정기 백업 수행.
4. 스케줄링 정책
ML 워크로드는 GPU 자원의 효율적 분배가 핵심이다.
이를 위해 Volcano + Kueue 조합으로 스케줄링을 설계했다.
4.1 Volcano (gang scheduling)
- 모든 GPU Pod가 동시에 slot을 확보해야 job을 시작함.
- 부분 할당으로 인한 자원 낭비를 방지하고, 멀티 GPU job의 deadlock을 예방.
4.2 Kueue (Fair/Borrowing/Preemption)
- 부서/프로젝트별 큐를 나눠서 GPU 점유율을 공정하게 관리.
- 유휴 GPU는 다른 팀이 일시적으로 “borrow” 가능.
- 긴급 job은 Preemption 정책으로 우선 처리.
결과적으로 Volcano는 Job 동시성 보장, Kueue는 조직 간 공정성 확보라는 역할 분담을 수행한다.
5. 모니터링 및 관제
Zabbix로 통합 모니터링을 구성한다.
- GPU/CPU utilization, Ceph I/O, InfiniBand Throughput, Kubernetes Pod 상태 등을 실시간 수집.
6. 설계 요약
| 항목 | 구성 요약 |
|---|---|
| 네트워크 | Ethernet(k8s control) + InfiniBand(GPU only) |
| GPU 스케줄링 | Volcano + Kueue |
| 스토리지 | 3-tier 구조 (NVMe / Ceph / MinIO) |
| 모니터링 | Zabbix 통합 감시 |
| 주요 목표 | GPU 효율 극대화, 고성능 I/O, 부서 간 공정 자원 분배 |
7. 확장 및 운영 포인트
- GPU 노드 확장 시 InfiniBand 스위치 포트 여유 고려.
- Ceph Cluster는 CPU 노드 3대 이상 MON/OSD 분리 배치로 안정성 확보.
- MinIO는 4개 노드 분산 구성으로 2노드 장애까지 내결함성 확보.
- Zabbix는 Slack, Mattermost 등으로 Alert 연동.
결론
이 구성은 단순한 Kubernetes 클러스터가 아니라,
“GPU 리소스 효율화 + 고성능 I/O + 스케줄링 공정성”을 모두 달성하는 ML 전용 On-Prem Platform이다.
GPU 노드에는 InfiniBand를, CPU 노드에는 Ceph를,
그리고 전체에는 Zabbix를 더해 — 관리성과 확장성까지 확보했다.
🛠 마지막 수정일: 2025.10.13
ⓒ 2025 엉뚱한 녀석의 블로그 [quirky guy's Blog]. All rights reserved. Unauthorized copying or redistribution of the text and images is prohibited. When sharing, please include the original source link.
💡 도움이 필요하신가요?
Zabbix, Kubernetes, 그리고 다양한 오픈소스 인프라 환경에 대한 구축, 운영, 최적화, 장애 분석,
광고 및 협업 제안이 필요하다면 언제든 편하게 연락 주세요.
📧 Contact: jikimy75@gmail.com
💼 Service: 구축 대행 | 성능 튜닝 | 장애 분석 컨설팅
📖 E-BooK [PDF] 전자책 (Gumroad):
Zabbix 엔터프라이즈 최적화 핸드북
블로그에서 다룬 Zabbix 관련 글들을 기반으로 실무 중심의 지침서로 재구성했습니다.
운영 환경에서 바로 적용할 수 있는 최적화·트러블슈팅 노하우까지 모두 포함되어 있습니다.
💡 Need Professional Support?
If you need deployment, optimization, or troubleshooting support for Zabbix, Kubernetes,
or any other open-source infrastructure in your production environment, or if you are interested in
sponsorships, ads, or technical collaboration, feel free to contact me anytime.
📧 Email: jikimy75@gmail.com
💼 Services: Deployment Support | Performance Tuning | Incident Analysis Consulting
📖 PDF eBook (Gumroad):
Zabbix Enterprise Optimization Handbook
A single, production-ready PDF that compiles my in-depth Zabbix and Kubernetes monitoring guides.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.