50-Node ML Kubernetes Cluster Design
This document explains how to design a Kubernetes cluster optimized for machine learning workloads in an on-premises environment combining both CPU and GPU nodes.
The core goals are efficient GPU resource utilization and high-performance I/O through a tiered storage architecture.
1. Overview
The cluster consists of 50 nodes (15 GPU + 35 CPU).
GPU nodes handle model training, while CPU nodes are used for data preprocessing, ingestion, and model serving.
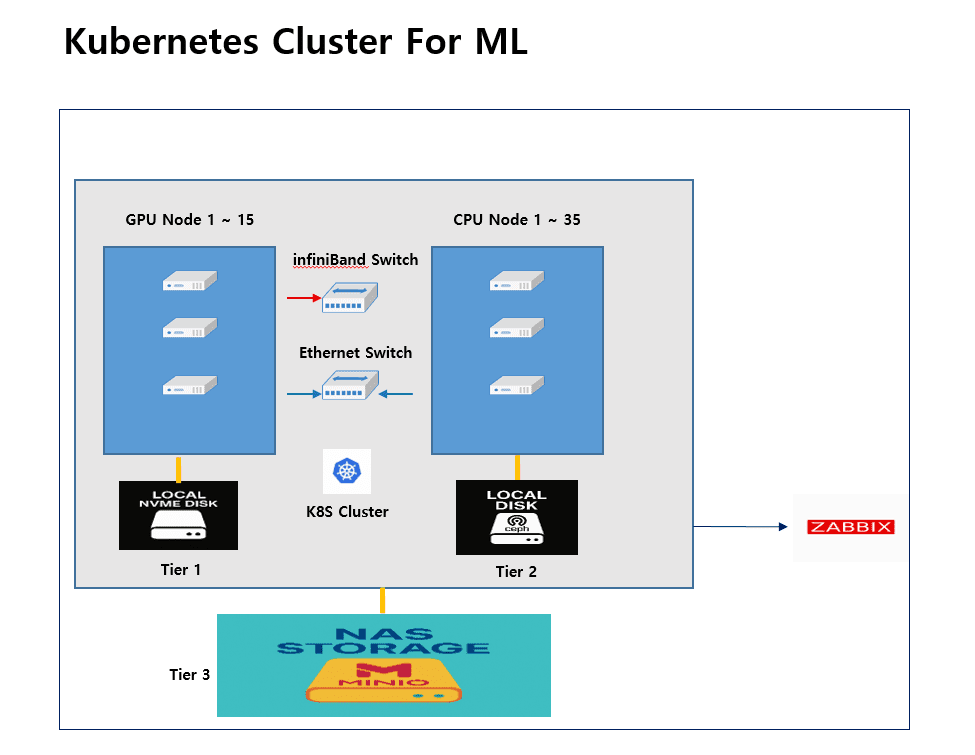
Architecture Summary:
- GPU Nodes (1–15): Tier 1 — Local NVMe disks
- CPU Nodes (1–35): Tier 2 — Ceph-based local storage
- NAS (MinIO): Tier 3 — Backup and long-term storage
- Networking: Hybrid InfiniBand + Ethernet configuration
2. Network Design (Ethernet + InfiniBand)
2.1 Architecture
Ethernet Switch
- Common across all nodes.
- Handles Kubernetes internal traffic such as control plane communication, API calls, and Pod networking.
InfiniBand Switch
- Used exclusively for GPU nodes.
- Provides high-performance RDMA links for distributed training (e.g., AllReduce, NCCL).
2.2 Implementation Policy
- Kubernetes manages only the Ethernet network (via CNI such as Cilium or Calico).
- InfiniBand is configured as an external network and accessed directly within Pods.
- Only GPU nodes have InfiniBand NICs enabled, creating a dedicated high-speed path for GPU-to-GPU communication.
This design eliminates unnecessary costs on CPU nodes while removing network bottlenecks in GPU clusters.
3. Tiered Storage Architecture
Machine learning workloads demand multiple types of storage for datasets, checkpoints, and model artifacts.
To handle this efficiently, the storage is divided into three tiers.
| Tier | Configuration | Purpose | Notes |
|---|---|---|---|
| Tier 1 | Local NVMe disks on GPU nodes | Scratch / Checkpoint only | Ultra-fast temporary storage, Local PV |
| Tier 2 | Ceph storage on CPU nodes | Dataset / Checkpoint storage | Uses Ceph RBD or CephFS |
| Tier 3 | NAS (MinIO backend) | Long-term retention / Backup | Object storage, S3-compatible |
3.1 Tier 1 — Local NVMe
- Each GPU node uses a local NVMe SSD as a Local Persistent Volume.
- Stores temporary checkpoints and intermediate files during training.
- Managed with a Delete reclaim policy to prioritize speed and simplicity.
3.2 Tier 2 — Ceph Cluster
- CPU node disks are aggregated into a Ceph cluster.
- Stores shared datasets and intermediate training results.
- GPU nodes can mount Ceph volumes for shared access across workloads.
3.3 Tier 3 — MinIO NAS
- Implements a MinIO-based object storage layer for long-term backups.
- Serves as a backup target for Ceph data.
- Synchronization is automated with tools like
mc mirrororrclone.
4. Scheduling Policy
Efficient GPU scheduling is crucial for ML workloads.
The cluster adopts a Volcano + Kueue combination for fairness and performance.
4.1 Volcano (Gang Scheduling)
- A job starts only when all required GPU slots are available.
- Prevents partial allocation and avoids deadlocks in multi-GPU workloads.
4.2 Kueue (Fairness / Borrowing / Preemption)
- Divides GPU resources into queues by project or department.
- Idle GPUs can be temporarily borrowed by other teams.
- Urgent jobs are prioritized through preemption.
In short, Volcano ensures job concurrency, while Kueue enforces fairness and responsiveness across multiple teams.
5. Monitoring and Observability
A Zabbix-based monitoring system is integrated for unified observability across nodes and services.
Monitored metrics include:
- GPU and CPU utilization
- Ceph I/O throughput
- InfiniBand bandwidth
- Kubernetes Pod and Node status
Zabbix Agent2 can be extended with Prometheus exporters for detailed GPU and storage metrics.
6. Design Summary
| Category | Configuration Summary |
|---|---|
| Network | Ethernet (K8s control) + InfiniBand (GPU only) |
| GPU Scheduling | Volcano + Kueue |
| Storage | 3-Tier: NVMe / Ceph / MinIO |
| Monitoring | Zabbix Unified Monitoring |
| Primary Goals | Maximize GPU efficiency, High-performance I/O, Fair resource sharing |
7. Scalability and Operations
- Ensure InfiniBand switch port capacity before expanding GPU nodes.
- Deploy Ceph MON and OSD daemons across at least three CPU nodes for HA.
- Configure MinIO in a 4-node distributed setup for 2-node fault tolerance.
- Integrate Zabbix alerts with Slack or Mattermost for real-time notifications.
- Supported workloads include PyTorch DDP, TensorFlow MultiWorkerMirroredStrategy, and Ray.
Conclusion
This cluster is not just a standard Kubernetes deployment —
it’s an ML-optimized on-prem platform designed for:
- Efficient GPU resource utilization
- High-performance, tiered storage
- Fair and responsive scheduling
By combining InfiniBand for GPU nodes, Ceph for shared data, and Zabbix for unified monitoring,
the system achieves both performance and manageability at scale.
🛠 마지막 수정일: 2025.10.13
ⓒ 2025 엉뚱한 녀석의 블로그 [quirky guy's Blog]. All rights reserved. Unauthorized copying or redistribution of the text and images is prohibited. When sharing, please include the original source link.
💡 도움이 필요하신가요?
Zabbix, Kubernetes, 그리고 다양한 오픈소스 인프라 환경에 대한 구축, 운영, 최적화, 장애 분석,
광고 및 협업 제안이 필요하다면 언제든 편하게 연락 주세요.
📧 Contact: jikimy75@gmail.com
💼 Service: 구축 대행 | 성능 튜닝 | 장애 분석 컨설팅
📖 E-BooK [PDF] 전자책 (Gumroad):
Zabbix 엔터프라이즈 최적화 핸드북
블로그에서 다룬 Zabbix 관련 글들을 기반으로 실무 중심의 지침서로 재구성했습니다.
운영 환경에서 바로 적용할 수 있는 최적화·트러블슈팅 노하우까지 모두 포함되어 있습니다.
💡 Need Professional Support?
If you need deployment, optimization, or troubleshooting support for Zabbix, Kubernetes,
or any other open-source infrastructure in your production environment, or if you are interested in
sponsorships, ads, or technical collaboration, feel free to contact me anytime.
📧 Email: jikimy75@gmail.com
💼 Services: Deployment Support | Performance Tuning | Incident Analysis Consulting
📖 PDF eBook (Gumroad):
Zabbix Enterprise Optimization Handbook
A single, production-ready PDF that compiles my in-depth Zabbix and Kubernetes monitoring guides.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.