Elasticsearchは単なる検索エンジンに留まらず、ログ・メトリクス・アプリケーションデータまで処理する分散データプラットフォームとして活用される。
そのため安定運用のためには、クラスタ状態・リソース使用量・性能・インデックス処理といった領域ごとの主要指標を定期的に確認する必要がある。
1. クラスタ状態指標
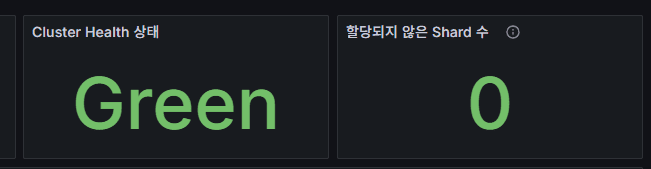
cluster_health
クラスタ全体の状態。
Green = 正常、Yellow = レプリカ不整合、Red = データ消失リスク。
unassigned_shards
割り当てられていないShardの数。
0が正常。ディスク不足・ノード障害・Shard再配置の遅延などで増加。
2. リソース指標

Total size of all file stores / Total available size to JVM in all file stores
全ファイルストアの総ディスク容量、およびJVMプロセスが実際に使用できる可用領域の合計。
新規Shardが追加可能かどうかを最も早く判断できる指標。
問題が発生するパターン:Availableが急速に減少するケース
- インデックス増加
- ログ急増
- Replica増加
ディスク使用量に応じた挙動:
- 85% 使用時:新規Shardが未割り当てに
- 90% 使用時:既存Shardが他ノードへ強制移動
- 95% 使用時:インデックスが read-only に設定
まとめ:
- “Total(総容量)にまだ余裕がある” と判断すると誤りになることが多い。
- 実運用では Available値が実質的な判断基準。
- Total size = 物理ストレージの総容量。
- Total available to JVM = Elasticsearchが実際に使える領域。
- JVM Heapとは無関係で、あくまでファイルシステム上の可用領域。
- 運用では Available を基準に監視し、Totalは参考値に過ぎない。
jvm heap usage percent
JVM Heap使用率。
- 85%以上が継続 → Full GC増加の可能性
- 95%以上 → OutOfMemoryの危険
node uptime
ノード稼働時間。
再起動が頻発する場合は障害前兆。
3. 性能指標
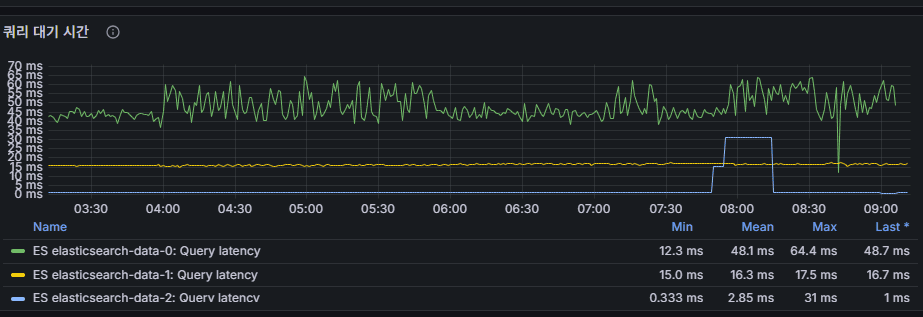

query latency
検索クエリ応答遅延。
ミリ秒単位で増加するとアプリケーション体感性能が低下。
service response_time
REST APIリクエストの応答速度。
継続的な増加はバックエンドリソースのボトルネックを示唆。
4. インデックス処理および接続指標
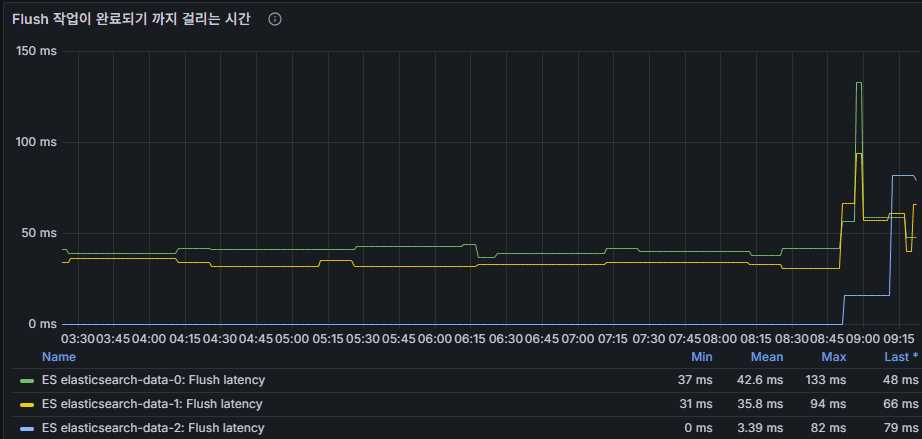
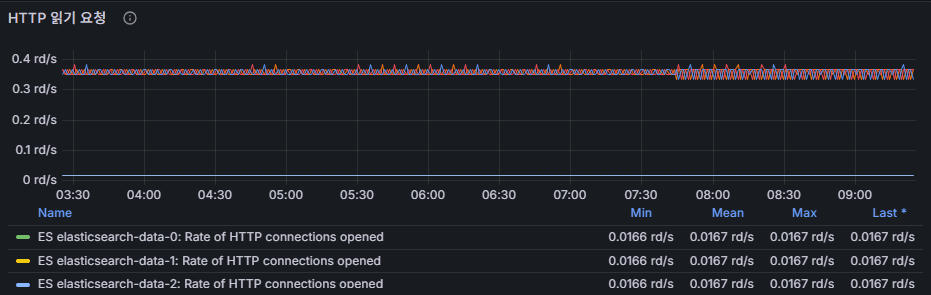
flush latency
flush処理にかかる時間。
ディスクI/Oのボトルネック確認に有効。
インデックス処理の流れ:
- 文書 → メモリバッファ → 新規segment生成(translogに記録)
- refresh → メモリバッファをsegmentへ変換し検索可能状態へ
- flush → translogをディスクへ安全に書き込み、segmentを固定化
運用解釈:
flush latency ↑ → ディスクI/O遅延、translog増加、
障害復旧時間の延伸につながる可能性
http connections opened(rd/s : reads per second)
開かれているHTTP接続数。
スパイクが発生した場合、クライアント側の負荷集中を疑う。
✅ 運用ポイントまとめ
- Cluster Health → 管理者が最優先で確認すべき安定性指標
- Disk容量 + JVM Heap → リソース逼迫を早期に検知
- Query Latency + Response Time → 性能ボトルネックの核心
- Flush Latency + HTTP接続数 → データ処理・クライアント負荷の状況判断
🛠 마지막 수정일: 2025.11.24
💡 お困りですか?
Zabbix、Kubernetes、各種オープンソースインフラの構築・運用・最適化・障害解析が必要であれば、いつでもご連絡ください。
📧 メール: jikimy75@gmail.com
💼 サービス: 導入支援 | 性能チューニング | 障害解析コンサルティング
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.