“복잡한 Zabbix 운영을 더 효율적으로 만들고 싶다면,
블로그의 핵심 내용을 집대성한 『Zabbix 엔터프라이즈 최적화 핸드북(PDF)』을 확인해보세요.”
https://jikimy.gumroad.com/l/zabbix-master
🧭 관련 글을 찾고 있다면, 검색창에 “모니터링 지표에 대한 고찰” 을 입력해 보세요.
Elasticsearch는 단순 검색 엔진을 넘어 로그·메트릭·애플리케이션 데이터까지 처리하는 분산 데이터 플랫폼으로 활용된다.
따라서 안정적 운영을 위해선 클러스터 상태·리소스 사용·성능·색인 처리 영역별 주요 지표를 주기적으로 점검해야 한다.
1. 클러스터 상태 지표
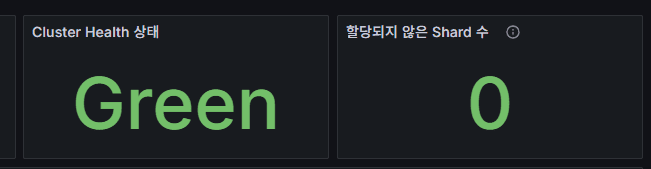
cluster_health
클러스터 전체 상태.
Green = 정상, Yellow = 복제본 불일치, Red = 데이터 유실 위험.
unassigned_shards
할당되지 않은 Shard 개수.
0이 정상. 디스크 부족, 노드 다운, 샤드 재배치 지연 시 증가.
2. 리소스 지표

Total size of all file stores / Total available size to JVM in all file stores
전체 디스크 용량과 JVM 프로세스가 실제로 쓸 수 있는 가용 공간의 합계.
Shard 추가 불가 여부를 가장 먼저 판별.
문제 발생 지점 : Available이 빠르게 감소 → 인덱스 증가/로그 폭증/Replica 증가
. 85% 사용시 : 신규 샤드 미할당
. 90% 사용시 : 기존 샤드 다른 노드로 강제 이동
. 95% 사용시 : 인덱스 read-only 설정
정리 :
Total을 보고 “아직 여유 많다”고 생각하면 오판.
실제 운영에선 Available 값이 훨씬 작을 수 있음.
Total size = 물리적 총 용량.
Total available to JVM : 실제 Elasticsearch가 쓸 수 있는 용량.
JVM Heap과는 전혀 무관, 파일시스템 가용 영역만 반영.
실제 운영에선 Available 기준으로 해야 하며, Total 값은 참고 지표에 불과.
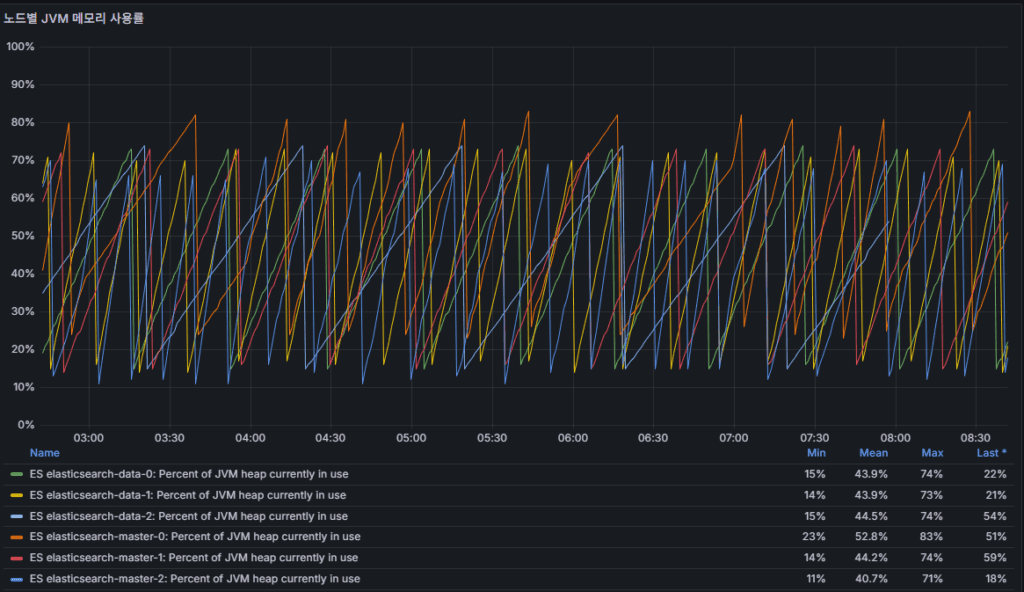
jvm heap usage percent
JVM Heap 사용률.
85% 이상 지속되면 Full GC 발생 횟수 증가 가능성.
95% 이상이면 OutOfMemory 위험.
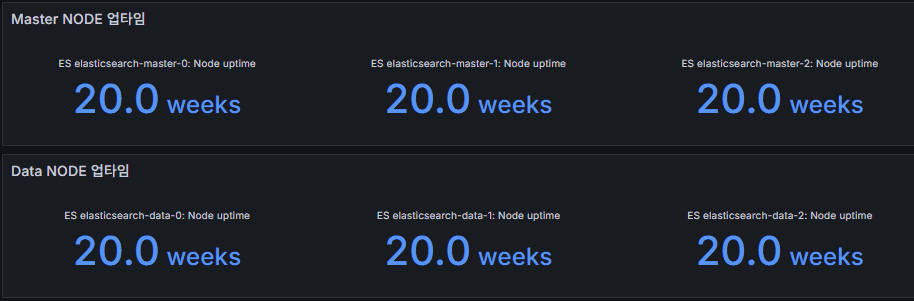
node uptime
노드 실행 시간.
잦은 재시작은 장애 전조.
3. 성능 지표
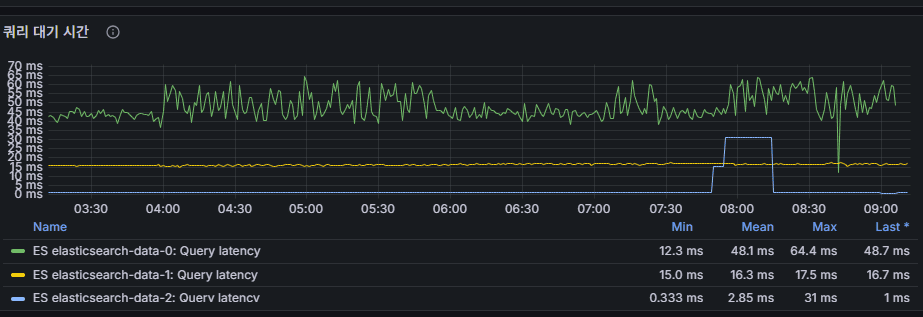

query latency
검색 쿼리 응답 지연 시간.
밀리초 단위로 증가 시 애플리케이션 체감 성능 저하.
service response_time
REST API 요청 응답 속도.
지속 증가하면 백엔드 리소스 병목 가능.
4. 색인 처리 및 연결 지표
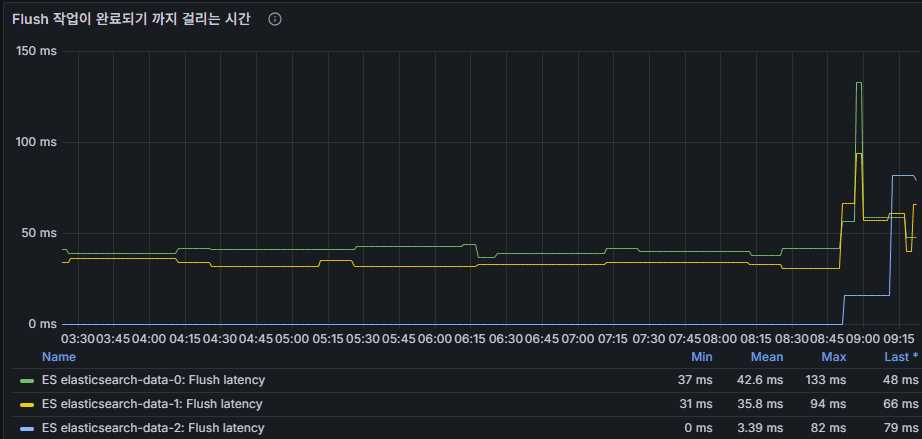
flush latency
flush 작업이 완료되는 데 걸린 시간.
디스크 I/O 병목 여부 확인 가능.
색인 처리 흐름:
. 문서 → 메모리 버퍼 → 새 segment 작성 (translog에 기록)
. refresh → 메모리 버퍼를 segment로 전환, 검색 가능 상태
. flush → translog를 디스크에 안전하게 기록하고 segment를 고정
운영 해석: flush latency ↑ → 디스크 I/O 지연, translog 크기 증가,
장애 복구 시간 지연 가능성
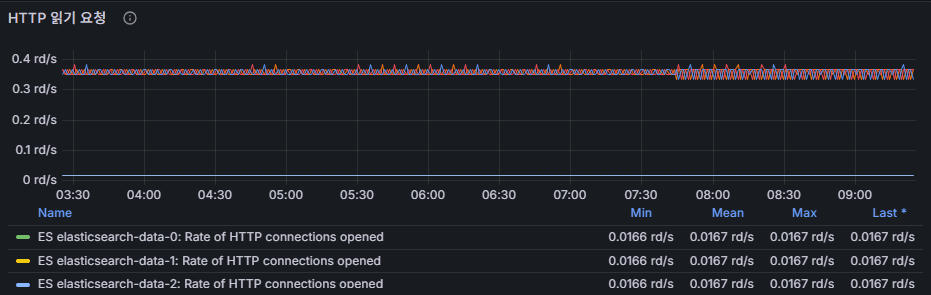
http connections opened (rd/s : reads per second)
열린 HTTP 연결 수.
스파이크 발생 시 클라이언트 부하 집중 의심.
✅ 운영 포인트 요약
- Cluster Health → 운영자가 가장 먼저 확인해야 할 안정성 지표.
- Disk 용량 파악 + JVM Heap → 리소스 한계 도달 여부를 빠르게 감지.
- Query Latency + Response Time → 성능 병목 파악 핵심.
- Flush Latency + http 연결수 → 데이터 처리 병목 여부 및 클라이언트 부하 판단.
🛠 마지막 수정일: 2025.12.22
ⓒ 2025 엉뚱한 녀석의 블로그 [quirky guy's Blog]. All rights reserved. Unauthorized copying or redistribution of the text and images is prohibited. When sharing, please include the original source link.
💡 도움이 필요하신가요?
Zabbix, Kubernetes, 그리고 다양한 오픈소스 인프라 환경에 대한 구축, 운영, 최적화, 장애 분석,
광고 및 협업 제안이 필요하다면 언제든 편하게 연락 주세요.
📧 Contact: jikimy75@gmail.com
💼 Service: 구축 대행 | 성능 튜닝 | 장애 분석 컨설팅
📖 E-BooK [PDF] 전자책 (Gumroad):
Zabbix 엔터프라이즈 최적화 핸드북
블로그에서 다룬 Zabbix 관련 글들을 기반으로 실무 중심의 지침서로 재구성했습니다.
운영 환경에서 바로 적용할 수 있는 최적화·트러블슈팅 노하우까지 모두 포함되어 있습니다.
💡 Need Professional Support?
If you need deployment, optimization, or troubleshooting support for Zabbix, Kubernetes,
or any other open-source infrastructure in your production environment, or if you are interested in
sponsorships, ads, or technical collaboration, feel free to contact me anytime.
📧 Email: jikimy75@gmail.com
💼 Services: Deployment Support | Performance Tuning | Incident Analysis Consulting
📖 PDF eBook (Gumroad):
Zabbix Enterprise Optimization Handbook
A single, production-ready PDF that compiles my in-depth Zabbix and Kubernetes monitoring guides.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.