“복잡한 Zabbix 운영을 더 효율적으로 만들고 싶다면,
블로그의 핵심 내용을 집대성한 『Zabbix 엔터프라이즈 최적화 핸드북(PDF)』을 확인해보세요.”
https://jikimy.gumroad.com/l/zabbix-master
🧭 관련 글을 찾고 있다면, 검색창에 “모니터링 지표에 대한 고찰” 을 입력해 보세요.
지난 글에서 MySQL 지표를 다뤘다면, 이번에는 Kafka를 살펴본다.
운영 환경에서 Kafka는 단순 메시지 큐를 넘어, 데이터 스트리밍 플랫폼으로 중요한 위치를 차지한다.
따라서 Kafka 브로커와 클러스터의 상태를 세밀하게 모니터링하는 것은 장애 예방과 성능 보장에 있어 필수적이다.
이번 글에서는 **Grafana 대시보드 (Zabbix 데이터 기반)**에서 제공되는 주요 Kafka 지표들을 중심으로 해석과 의미를 정리해 본다.
1. Offline Partitions Count
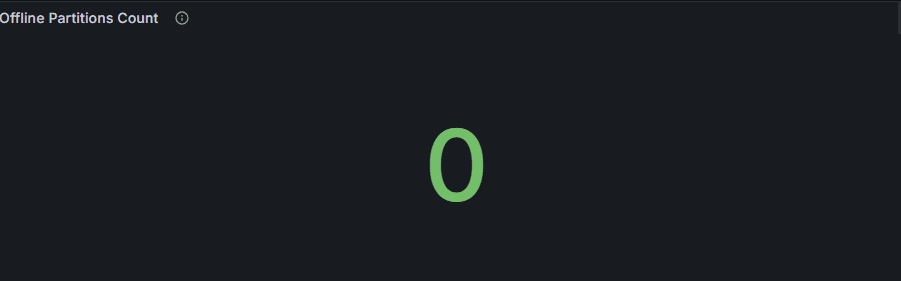
- 의미: 클러스터 내에서 리더를 잃어 접근 불가능해진 파티션의 개수.
- 정상 상태: 0.
- 비정상 상황: 특정 브로커 장애, 네트워크 단절, 디스크 I/O 불능 시 발생.
👉 운영 포인트: Offline Partition이 하나라도 나오면 데이터 유실 가능성이 높으므로 즉시 원인 확인 필요.
2. Under Replicated Partitions (URP)
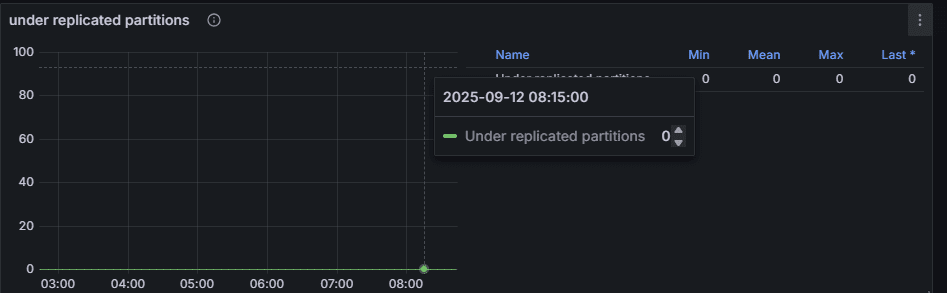
- 의미: 리더 파티션이 보유한 최신 데이터와 팔로워 파티션이 동기화되지 못한 상태.
- 정상 상태: 0.
- 비정상 상황: 브로커 과부하, 네트워크 지연, ISR 축소 시 발생.
👉 운영 포인트: URP는 Kafka 운영에서 가장 중요한 경보 지표다. 잠깐 발생해도 위험 신호, 지속된다면 클러스터 리소스 증설/장애 대응 필요.
3. GC Pause
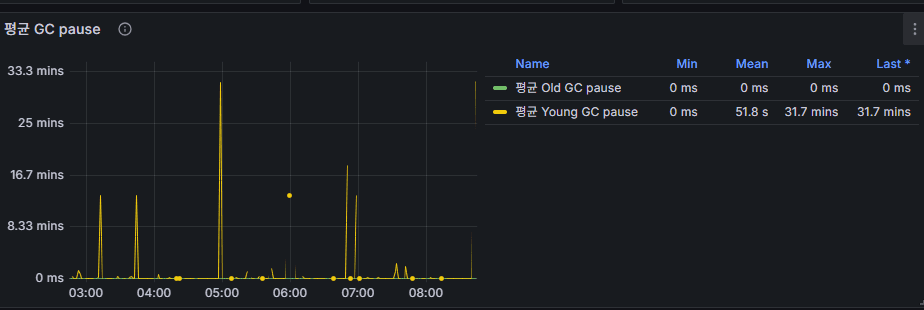
- 의미: 브로커 JVM에서 Garbage Collection(GC)이 실행될 때 애플리케이션이 멈추는 시간.
- Young GC (Minor GC): 짧고 잦음 → 보통 큰 문제는 아님.
- Old GC (Full GC): 드물지만 수백 ms~수초 발생 시 브로커가 사실상 정지.
👉 운영 포인트: 평균 pause time이 높아지면 메시지 처리 지연으로 이어진다. Heap 메모리 사이즈와 GC 튜닝을 함께 모니터링해야 한다.
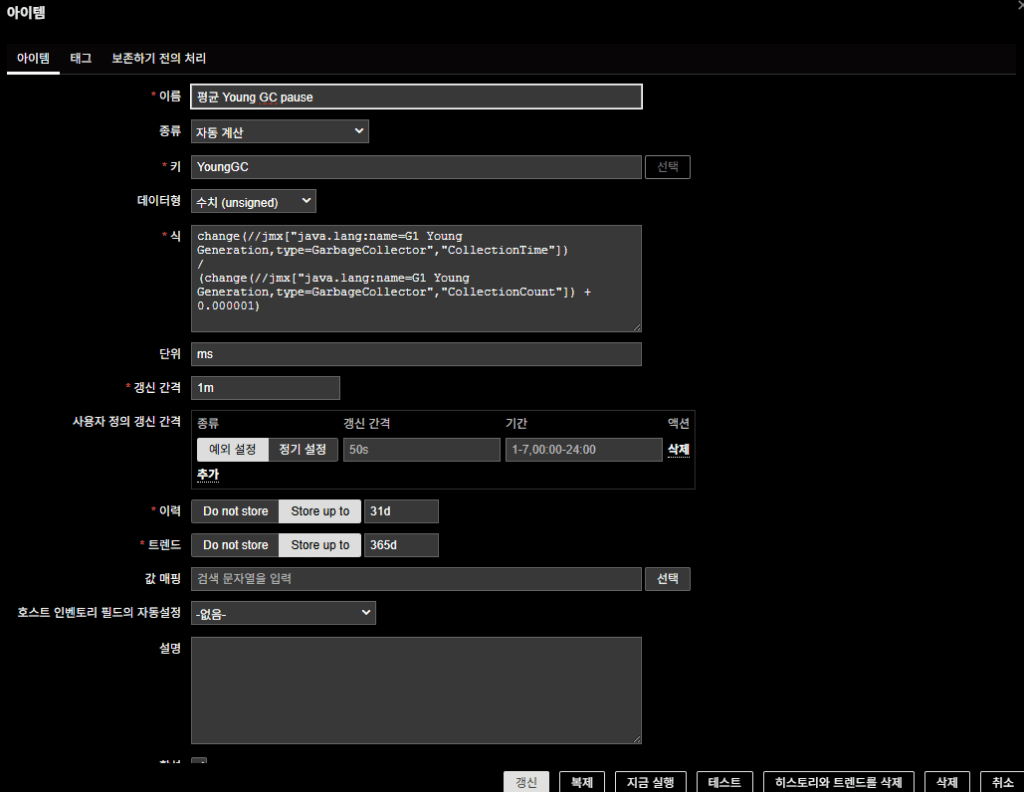
GC Pause 지표값에 대한 item은 zabbix의 Apache Kafka by JMX / Generic Java JMX 템플릿에 기본적으로 존재하지 않는다.이미 존재하는 아이템들을 이용해 아래와 같이 아이템을 신규로 작성한 부분이니 참고 바람
- 수식
change(//jmx[“java.lang:name=G1 Young Generation,type=GarbageCollector”,”CollectionTime”])
/
(change(//jmx[“java.lang:name=G1 Young Generation,type=GarbageCollector”,”CollectionCount”]) + 0.000001)
4. Heap Memory 사용률
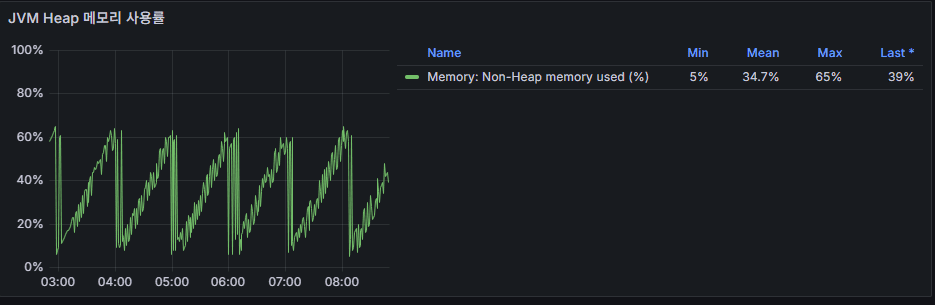
- 의미: Kafka 브로커 JVM Heap의 사용 현황.
- 정상 상태: 60~80% 사이에서 안정적으로 유지.
- 비정상 상황: 90% 이상 치솟으면 OutOfMemoryError, Full GC 연쇄 발생 가능.
👉 운영 포인트: Heap 사용률 그래프는 GC Pause와 반드시 같이 보아야 한다. 사용률이 높으면서 GC Pause가 증가한다면 조정 필요.
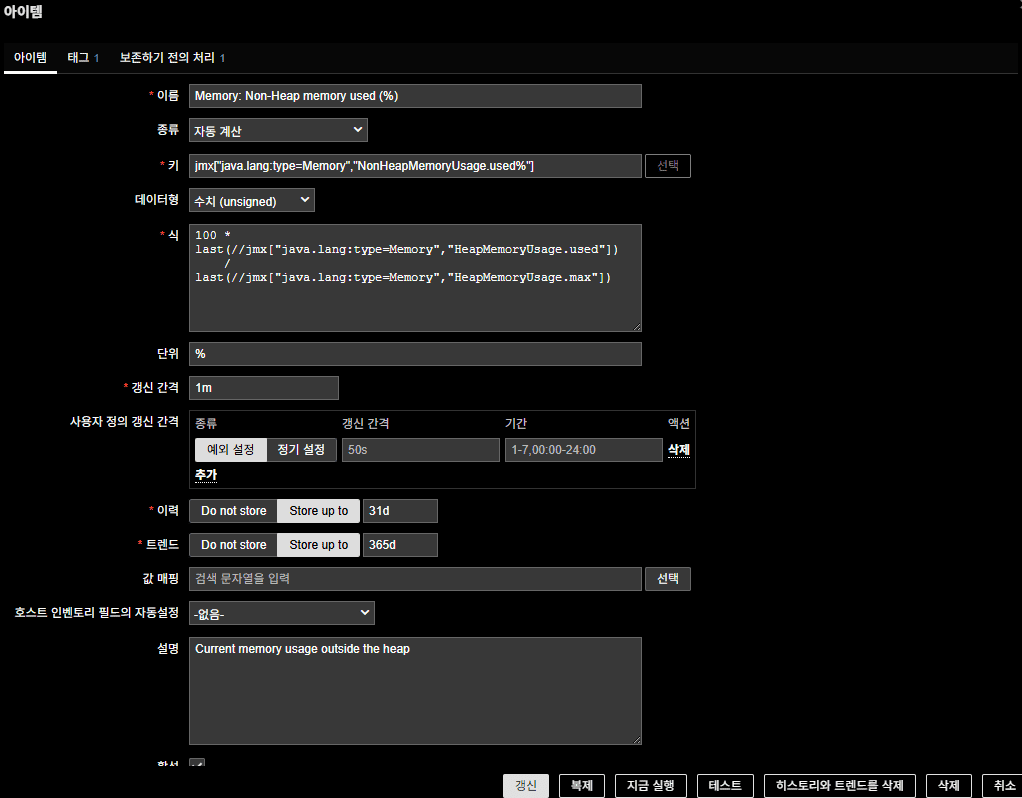
jvm heap memory 사용률도 템플릿에 포함되지 않은 아이템이다.역시나
이미 존재하는 아이템들을 이용해서 수식을 이용해 아이템을 신규로 작성한 부분이니 참고바란다.
- 수식
100 * last(//jmx[“java.lang:type=Memory”,”HeapMemoryUsage.used”])
/
last(//jmx[“java.lang:type=Memory”,”HeapMemoryUsage.max”])
5. 메시지 처리량 (Message Throughput)
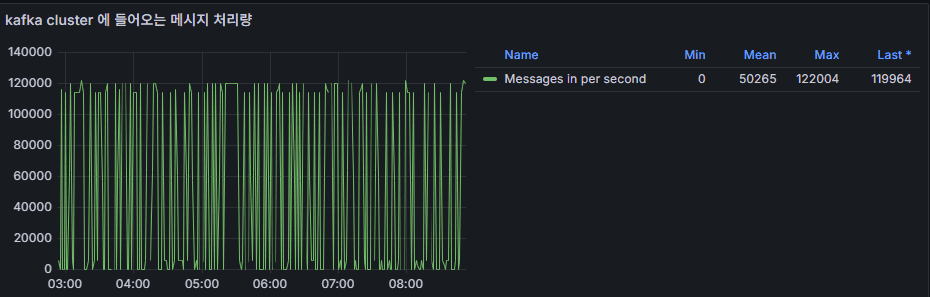
- 의미: 초당 처리되는 메시지 수 (Messages In / Out Per Second).
- 활용: 트래픽 패턴 분석, 부하 시점 확인, 장애 발생 시 병목 구간 추적.
- 비정상 상황: 특정 토픽 처리량 급감 → Producer/Consumer 문제 가능.
👉 운영 포인트: Throughput은 단독보다는 Consumer Lag, Broker Latency와 함께 해석해야 원인 파악 가능.
6. Kafka Cluster 입출력 트래픽
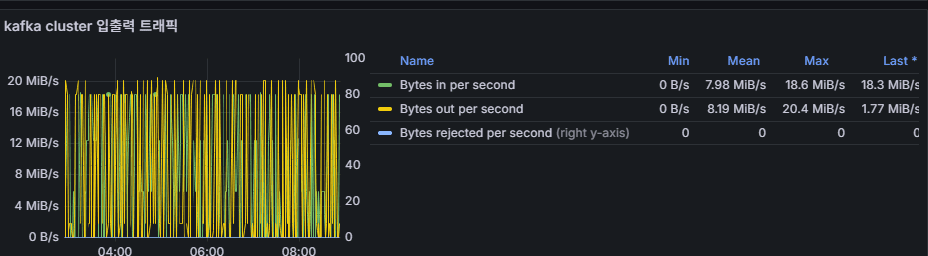
- 의미: 브로커 단위의 네트워크 트래픽 (MB/s 단위).
- 활용: 토픽/파티션 부하 분산 상태 확인.
- 비정상 상황: 특정 브로커만 트래픽이 몰리면 파티션 리더 불균형 가능성.
👉 운영 포인트: Producer 메시지 크기, 배치 사이즈 증가도 네트워크 트래픽 상승으로 이어진다. 브로커별 밸런싱 점검 필요.
7. ISR(In-Sync Replicas) 변화
- ISR 정의: Kafka에서 각 파티션의 리더와 동기화된 팔로워(replica) 집합.
- 리더 파티션에 쓰여진 메시지가 팔로워에도 복제되면 해당 팔로워는 ISR에 포함.
- ISR이 줄어든다는 건, 일부 팔로워가 동기화 불능 상태라는 의미.
- 정상 상태: 각 파티션의 replica 수와 ISR 수가 동일.
- 비정상 상황: ISR 수가 줄면 데이터 내구성 위험 → 브로커 장애 시 메시지 손실 가능.
“replica 수와 ISR 수가 동일하다”는 의미
- 정상 상태: replica 수 = ISR 수
→ 모든 복제본이 리더와 완전히 동기화. 데이터 내구성 100% 보장. - ISR Shrink (축소):
- ISR 수 < replica 수 (빠진 팔로워 존재)
- = ISR이 줄어든 상태
- → 팔로워가 리더 따라잡지 못함 (지연, 네트워크, 브로커 과부하 등).
- 동반 지표: URP 증가
- ISR Expand (확장):
- ISR 수 ↑ replica 수에 재접근
- = ISR이 늘어난 상태
- → 탈락했던 팔로워가 리더를 따라잡고 복귀.
- 정상화 과정.
즉,
- replica 수는 고정된 토픽 속성 (변하지 않음).
- ISR 수는 변동되는 운영 지표 (Shrink ↔ Expand 이벤트로 변함).
- 따라서 “동일하다” = Expand 완료 후 정상 상태,
“작다” = Shrink가 발생한 상태.
👉 운영 포인트: ISR 변화는 URP 지표와 직결된다. ISR 축소 → URP 증가 → 데이터 손실 위험. 반드시 알람 설정해야 한다.
정리
Kafka Grafana 대시보드(Zabbix 데이터 기반)에서 꼭 봐야 할 지표는 다음과 같다:
- Offline Partitions Count – 데이터 접근 가능 여부
- Under Replicated Partitions – 데이터 신뢰성
- GC Pause / Heap Memory – JVM 안정성
- Message Throughput – 처리 성능
- Cluster I/O Traffic – 네트워크 병목
- ISR 변화 – 데이터 내구성
Kafka는 개별 지표만 보는 것이 아니라, 지표 간 상관관계를 읽어야 한다.
예를 들어, Heap 사용률 증가 → GC Pause 증가 → 메시지 처리량 감소 → URP 증가라는 연쇄 반응을 조기에 포착하는 것이 운영자의 역할이다.
🛠 마지막 수정일: 2025.12.22
ⓒ 2025 엉뚱한 녀석의 블로그 [quirky guy's Blog]. All rights reserved. Unauthorized copying or redistribution of the text and images is prohibited. When sharing, please include the original source link.
💡 도움이 필요하신가요?
Zabbix, Kubernetes, 그리고 다양한 오픈소스 인프라 환경에 대한 구축, 운영, 최적화, 장애 분석,
광고 및 협업 제안이 필요하다면 언제든 편하게 연락 주세요.
📧 Contact: jikimy75@gmail.com
💼 Service: 구축 대행 | 성능 튜닝 | 장애 분석 컨설팅
📖 E-BooK [PDF] 전자책 (Gumroad):
Zabbix 엔터프라이즈 최적화 핸드북
블로그에서 다룬 Zabbix 관련 글들을 기반으로 실무 중심의 지침서로 재구성했습니다.
운영 환경에서 바로 적용할 수 있는 최적화·트러블슈팅 노하우까지 모두 포함되어 있습니다.
💡 Need Professional Support?
If you need deployment, optimization, or troubleshooting support for Zabbix, Kubernetes,
or any other open-source infrastructure in your production environment, or if you are interested in
sponsorships, ads, or technical collaboration, feel free to contact me anytime.
📧 Email: jikimy75@gmail.com
💼 Services: Deployment Support | Performance Tuning | Incident Analysis Consulting
📖 PDF eBook (Gumroad):
Zabbix Enterprise Optimization Handbook
A single, production-ready PDF that compiles my in-depth Zabbix and Kubernetes monitoring guides.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.