前回の記事では MySQL の指標を扱ったが、今回は Kafka を取り上げる。
運用環境において Kafka は単なるメッセージキューではなく、
データストリーミングプラットフォームとして重要な役割を担う。
そのため Kafka ブローカーおよびクラスタ状態を細かく監視することは、
障害予防や性能保証に不可欠である。
本稿では Grafana ダッシュボード(Zabbix データベース連携) に表示される主要な Kafka 指標について、
その意味と読み解き方を整理する。
1. Offline Partitions Count
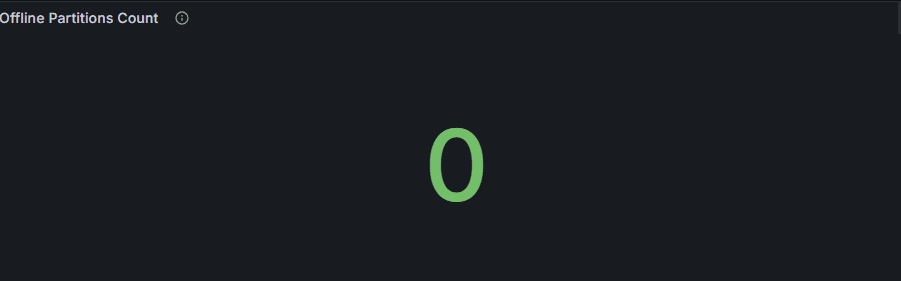
意味:クラスタ内でリーダーを失い、アクセス不能になったパーティション数。
正常値:0
異常時:ブローカー障害、ネットワーク断、ディスク I/O 不全などで発生。
👉 運用ポイント:Offline Partition が 1 つでも出ればデータロスの可能性が高く、即時原因調査が必要。
2. Under Replicated Partitions(URP)
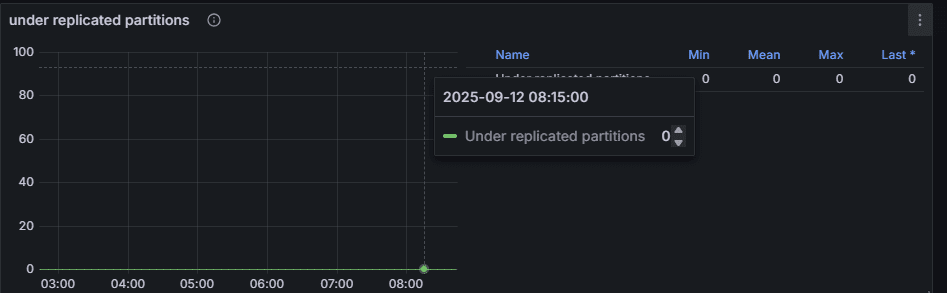
意味:リーダーパーティションの最新データをフォロワーが同期できていない状態。
正常値:0
異常時:ブローカー過負荷、ネットワーク遅延、ISR 縮小など。
👉 運用ポイント:URP は Kafka 運用で最重要警告指標。
瞬間的でも危険信号、継続するならリソース増強または障害対応が必要。
3. GC Pause
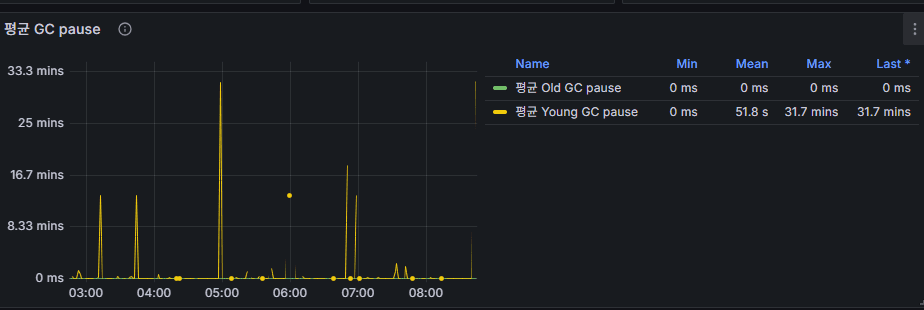
意味:Kafka ブローカー JVM の Garbage Collection 実行時にアプリケーションが停止する時間。
- Young GC(Minor GC):短く頻繁 → 通常は大きな問題ではない
- Old GC(Full GC):稀だが数百 ms〜数秒の場合、ブローカーが実質停止状態
👉 運用ポイント:平均 pause time が増えるとメッセージ処理遅延につながる。
Heap サイズと GC チューニングを併せて監視する必要がある。
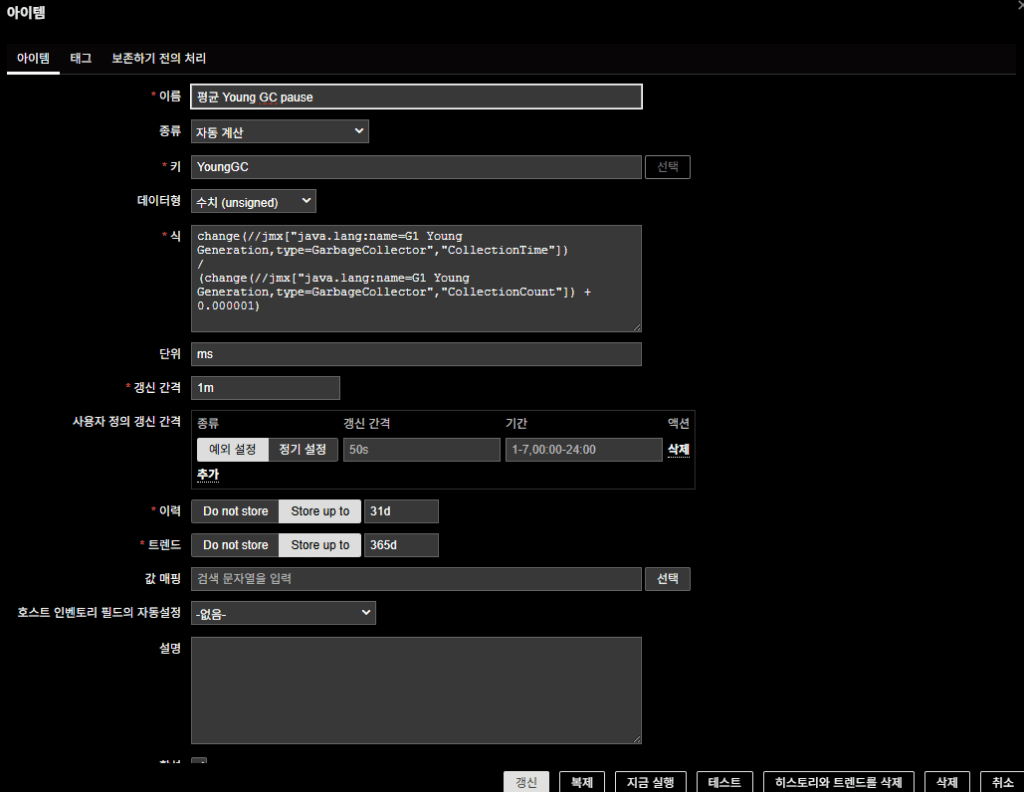
GC Pause 指標は Zabbix の Apache Kafka by JMX / Generic Java JMX テンプレートに含まれていない。
既存アイテムを組み合わせて以下のように新規アイテムを作成したものなので参考にしてほしい。
数式
change(//jmx["java.lang:name=G1 Young Generation,type=GarbageCollector","CollectionTime"])
/
(change(//jmx["java.lang:name=G1 Young Generation,type=GarbageCollector","CollectionCount"]) + 0.000001)
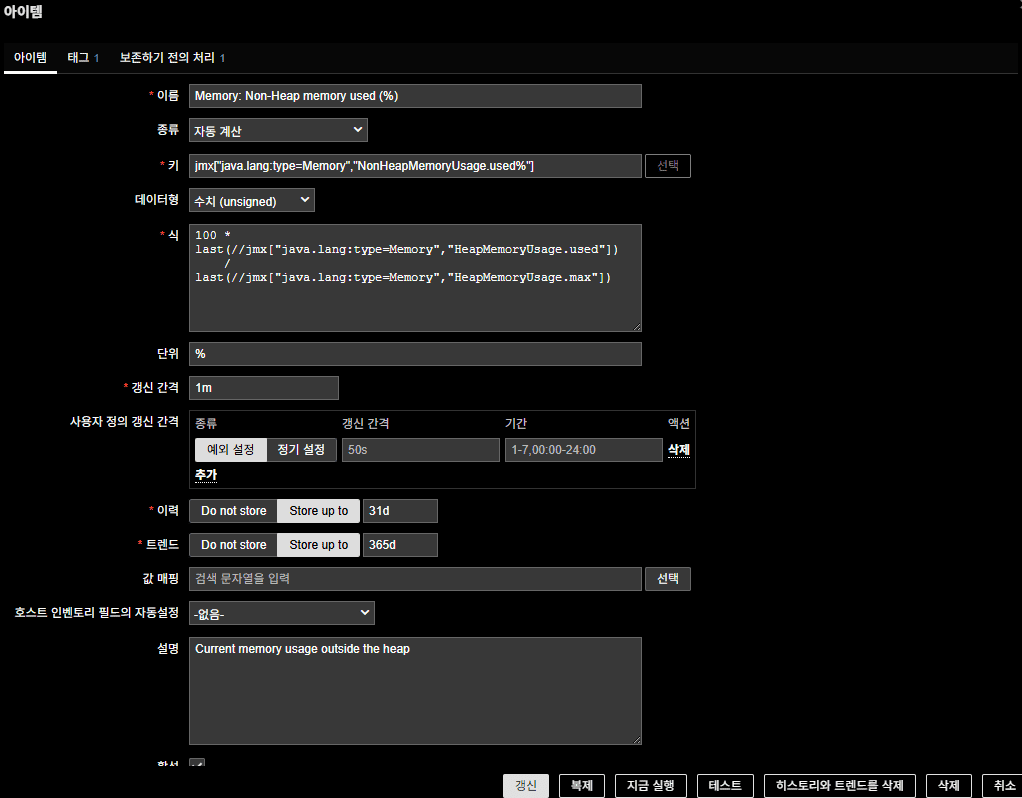
4. Heap Memory 使用率
意味:Kafka ブローカー JVM Heap の使用状況。
正常値:60〜80% 程度
異常時:90% を超えると OutOfMemoryError、Full GC の連鎖が発生する可能性。
👉 運用ポイント:Heap 使用率は GC Pause と必ず組み合わせて確認する。
使用率が高く GC Pause も増えている場合は調整が必要。
Heap Memory 使用率もテンプレートに含まれていないため、
既存 JMX アイテムから以下のように自作したものである。
数式
100 * last(//jmx["java.lang:type=Memory","HeapMemoryUsage.used"])
/
last(//jmx["java.lang:type=Memory","HeapMemoryUsage.max"])
5. メッセージ処理量(Message Throughput)
意味:1 秒あたりのメッセージ処理数(Messages In / Out Per Second)。
用途:トラフィックパターン分析、負荷ピーク検知、障害発生時のボトルネック特定。
異常時:特定トピックの処理量急減 → Producer / Consumer 側の問題可能性。
👉 運用ポイント:Throughput は単独ではなく、
Consumer Lag / Broker Latency と併せて解釈することで原因特定が容易になる。
6. Kafka Cluster 入出力トラフィック
意味:ブローカー単位のネットワークトラフィック(MB/s)。
用途:トピック/パーティション負荷分散の偏り確認。
異常時:特定ブローカーだけトラフィック集中 → パーティションリーダーの偏在。
👉 運用ポイント:Producer のメッセージサイズやバッチサイズ増加も
ネットワーク負荷に直結するため、ブローカー間のバランスを確認する必要がある。
7. ISR(In-Sync Replicas)の変動
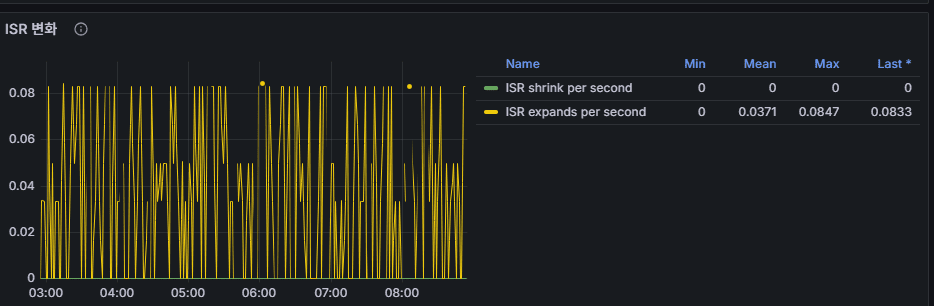
ISR とは:リーダーと同期されたフォロワー(replica)集合。
リーダーに書き込まれたデータがフォロワーにも複製されると ISR に含まれる。
正常状態:replica 数 = ISR 数
→ 全レプリカが完全同期 = データ耐久性 100%
ISR Shrink(縮小)
ISR 数 < replica 数 (フォロワーが1つ以上脱落)
- 遅延
- ネットワーク問題
- ブローカー過負荷
などで発生
→ URP 増加と直結
ISR Expand(拡大)
脱落したフォロワーがリーダーを追いつき ISR に復帰した状態。
👉 運用ポイント:ISR の変化は URP と強く結びつく。
ISR 縮小 → URP 増加 → データロスリスク。必ずアラート設定が必要。
まとめ
Kafka の Grafana ダッシュボード(Zabbix データ基盤)で特に確認すべき指標:
- Offline Partitions Count:データアクセス可否
- Under Replicated Partitions:データ信頼性
- GC Pause / Heap Memory:JVM 安定性
- Message Throughput:処理性能
- Cluster I/O Traffic:ネットワーク負荷
- ISR 変動:データ耐久性
Kafka は単一指標だけを見ても意味がなく、
指標間の相関を読むことが運用者の役割である。
例:
Heap 使用率上昇 → GC Pause 増加 → メッセージ処理量低下 → URP 増加
このような連鎖的な悪化を早期に検知できるかが、安定運用の鍵となる。
🛠 마지막 수정일: 2025.11.19
💡 お困りですか?
Zabbix、Kubernetes、各種オープンソースインフラの構築・運用・最適化・障害解析が必要であれば、いつでもご連絡ください。
📧 メール: jikimy75@gmail.com
💼 サービス: 導入支援 | 性能チューニング | 障害解析コンサルティング
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.