시스템 엔지니어라면 TIME_WAIT이라는 글자를 안 본 사람은 없을 거다.ss -tan 명령어 한 번만 실행해도 어김없이 수백 개는 떠 있다.
대부분 처음엔 “이거 리소스 낭비 아냐?”라고 생각한다.
하지만 이 상태는 결코 ‘불필요한 잔재’가 아니다.
TCP가 데이터 유실 없이 통신을 끝내기 위해 남겨둔,
일종의 사후 안정 구간이다.
TCP 종료는 “닫기”가 아니라 “정리 과정” 이다
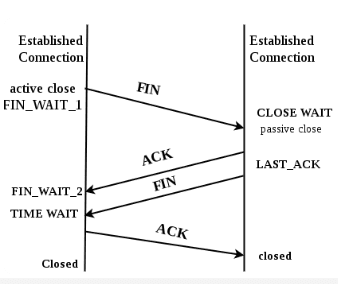
TCP는 단순히 “끝났다”로 끝나지 않는다.
서버와 클라이언트가 서로 FIN과 ACK를 주고받으며
각자 자신이 마지막으로 보낸 데이터가 완전히 도착했는지 확인한다.
이 과정을 4-way handshake라고 부른다.
이때 먼저 종료를 요청한 쪽 — 보통 클라이언트가 —
잠깐 머물러 있게 된다.
바로 그때의 상태가 TIME_WAIT이다.
이 시점의 소켓은 이미 닫힌 것처럼 보이지만,
커널 입장에서는 여전히 **“마지막 ACK가 유효했는가”**를 검증하는 중이다.
만약 네트워크 지연으로 인해
상대방이 재전송하는 FIN을 다시 받게 된다면,
이 소켓은 잠시 부활해 재응답을 수행한다.
즉, **TIME_WAIT은 ‘죽은 연결을 되살리는 짧은 생명 연장 구간’**인 셈이다.

TIME_WAIT은 시스템 자원을 얼마나 차지하나?
TIME_WAIT을 싫어하는 이유 중 하나는 “리소스 낭비”라는 인식 때문이다.
하지만 실제로는 현대 리눅스 커널에서 그 부담은 거의 없다.
각 TIME_WAIT 소켓은 커널의 tcp_timewait_sock 구조체로 관리되며,
여기엔 IP, 포트, 타임스탬프, 시퀀스 등
재전송을 식별하는 최소한의 정보만 담긴다.
한 소켓이 차지하는 크기는 수백 바이트 남짓에 불과하다.
이를 실제 운영 환경으로 옮겨보자.
수만 개의 TIME_WAIT 소켓이 동시에 존재한다 해도
메모리 사용량은 수십 MB 수준에 머문다.
요즘처럼 수 GB 메모리를 가진 서버 환경에서는
그 정도는 로그 캐시보다도 가볍다.
오히려 이 상태를 무리하게 줄이거나tcp_tw_reuse 같은 옵션으로 재활용을 강제하면,
희귀하지만 치명적인 문제 —
잘못된 세션 재활용, 데이터 혼선, 클라이언트 포트 충돌 — 이 발생할 수 있다.
TIME_WAIT의 수명 — 커널이 정해놓은 60초
TCP 사양은 MSL(Maximum Segment Lifetime) 개념을 정의한다.
네트워크 상에서 데이터가 살아 있을 최대 시간을 의미하며,
TIME_WAIT은 이 MSL의 두 배로 유지된다.
리눅스에서는 이 값이 커널 소스 코드에 하드코딩되어 있다.
대략 60초 정도이며,
사용자가 /proc이나 sysctl로 직접 변경할 수 없다.
즉, TIME_WAIT이 유지되는 시간은 시스템 전체의 안전 장치이지
엔지니어가 임의로 단축시킬 수 있는 ‘튜닝 값’이 아니다.
“이거 메모리 잡아먹는 거 아냐?” — 숫자로 보면 다르다
많은 운영자들이 TIME_WAIT을 보면
“소켓이 너무 많아서 메모리 낭비 아니냐”고 묻는다.
하지만 실제로 커널이 유지하는 정보량은 매우 작다.
TIME_WAIT 소켓은tcp_timewait_sock이라는 경량 구조체로 관리된다.
여기에는 IP, 포트, 타임스탬프, 시퀀스 넘버 등
재전송을 검증하기 위한 최소한의 정보만 담긴다.
커널 버전마다 조금씩 다르지만 수백 바이트 수준이다.
결국 TIME_WAIT은 “보호 비용”이지 “낭비”가 아니다.
TIME_WAIT이 많다고 서버가 느려지는 건 아니다
TIME_WAIT이 쌓인다고 해서
CPU가 느려지거나 시스템이 멈추는 일은 없다.
대부분의 경우, 커널은
TIME_WAIT 소켓을 전용 공간에서 관리하며
별도의 스케줄링 부하 없이 정리한다.
진짜 문제가 되는 건 포트 고갈이다.
클라이언트가 짧은 주기로 같은 서버에
수천 개의 연결을 반복적으로 생성하면,
사용 가능한 로컬 포트 범위가 소진될 수 있다.
리눅스 기본 로컬 포트 범위(/proc/sys/net/ipv4/ip_local_port_range)는
보통 32,768~60,999 정도이며, 커널 버전이나 배포판에 따라 약간 다르다.
이 범위를 다 써버리면 새로운 연결이 지연되거나 실패한다.
하지만 TIME_WAIT 자체가 느리게 만드는 건 아니다.
클라이언트 설계 문제일 뿐이다.
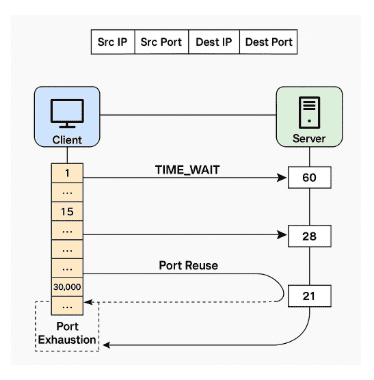
아래 그림은 TIME_WAIT 상태에서
포트가 어떻게 재사용되는지 단순화한 개념도다.
TIME_WAIT과 포트 고갈 — 서버는 안전하고, 클라이언트가 문제다
TIME_WAIT이 많다고 해서 서버의 포트가 고갈되진 않는다.
서버는 bind() 단계에서 하나의 포트(예: 443) 만 열어두고,
새로운 연결이 들어올 때마다 해당 포트에 새로운 소켓(fd) 을 할당해 관리한다.
즉, 서버는 고정된 하나의 포트를 여러 소켓으로 매핑해 쓰기 때문에
TIME_WAIT이 아무리 많아도 “포트 부족” 현상은 생기지 않는다.
문제는 클라이언트 쪽이다.
클라이언트는 서버에 연결할 때마다
자신의 로컬 포트 범위(/proc/sys/net/ipv4/ip_local_port_range) 중 하나를 임시로 할당받는다.
이 범위는 기본적으로 32768–60999 정도이며,
한정된 포트 수를 초과하면 더 이상 새로운 연결을 만들 수 없다.
그래서 클라이언트가 짧은 주기로 같은 서버에
수천 개의 TCP 연결을 반복적으로 맺으면 TIME_WAIT 상태의 포트들이 일시적으로 묶이고,
새 연결에 쓸 로컬 포트가 남지 않아 지연이나 실패가 발생할 수 있다.
리눅스 커널은 이 문제를 완화하기 위해
같은 로컬 포트를 재사용할 수 있는 몇 가지 조건을 두고 있다.
TCP 연결은 (src IP, src port, dst IP, dst port, protocol) 로 구분되기 때문에,
서버 주소나 대상 포트가 다르면 같은 로컬 포트를 다시 사용할 수 있다.
또한 tcp_tw_reuse(TIME_WAIT 소켓 재사용) 같은 옵션을 통해
일정 조건에서 TIME_WAIT 포트를 재활용하도록 허용할 수도 있지만,
최신 커널에서는 이미 안전하게 자동 재활용을 수행하므로
일반적으로 건드릴 필요가 없다.
정리하면,
TIME_WAIT은 서버의 부하 요인이 아니라 클라이언트의 포트 재사용 한계에서 오는 자연스러운 현상이다.
이건 시스템 튜닝이 아니라 연결 패턴의 설계 문제다.
tcp_tw_reuse? tcp_tw_recycle? — 잊어도 된다
옛날엔 tcp_tw_reuse나 tcp_tw_recycle을 켜서
TIME_WAIT 소켓을 재활용하는 경우가 있었다.
하지만 지금은 그럴 필요가 없다.
tcp_tw_recycle은 이미 커널 4.12에서 제거됐다.- 최신 커널(5.x~6.x)은 TIME_WAIT 소켓 관리 알고리즘이 개선돼
필요 시 포트를 안전하게 재사용하도록 처리한다.
즉, TIME_WAIT을 줄이는 건 “최적화”가 아니라 “위험요소”일 수 있다.
커널이 이미 알아서 최선의 균형을 잡고 있다는 점을 명심해야 한다.
결국 TIME_WAIT은 TCP의 ‘마지막 양심’이다
TIME_WAIT은 잘 동작하는 시스템의 징후다.
데이터를 잃지 않기 위해
커널이 스스로 한 번 더 확인하는 과정이다.
이걸 없애려 하는 건,
비행기에서 안전벨트를 귀찮다고 자르는 것과 같다.
정리
- TIME_WAIT은 TCP의 정상 종료 절차다.
- 유지 시간은 약 60초이며 커널에 하드코딩되어 있다.
- 메모리 부담은 미미하고 CPU 부하는 거의 없다.
- 포트 고갈은 애플리케이션 설계의 문제이며, 클라이언트쪽에서만 발생한다
- 커널 옵션으로 재활용을 강제하는 건 더 큰 문제를 부른다.
- TIME_WAIT이 많다는 건,
네트워크가 제대로 닫히고 있다는 증거다.
TIME_WAIT은 남아 있는 패킷이 세상에서 완전히 사라질 때까지
잠시 문을 붙잡고 있는 손이다.
그 손을 함부로 떼면, 데이터가 미처 다 떠나지 못한 채
닫혀버릴 수도 있다.
결국 TIME_WAIT은 TCP가 끝까지 신뢰를 지키는 마지막 단계다.
🛠 마지막 수정일: 2025.11.12
ⓒ 2025 엉뚱한 녀석의 블로그 [quirky guy's Blog]. All rights reserved. Unauthorized copying or redistribution of the text and images is prohibited. When sharing, please include the original source link.
💡 도움이 필요하신가요?
Zabbix, Kubernetes, 그리고 다양한 오픈소스 인프라 환경에 대한 구축, 운영, 최적화, 장애 분석이 필요하다면 언제든 편하게 연락 주세요.
📧 Contact: jikimy75@gmail.com
💼 Service: 구축 대행 | 성능 튜닝 | 장애 분석 컨설팅
💡 Need Professional Support?
If you need deployment, optimization, or troubleshooting support for Zabbix, Kubernetes, or any other open-source infrastructure in your production environment, feel free to contact me anytime.
📧 Email: jikimy75@gmail.com
💼 Services: Deployment Support | Performance Tuning | Incident Analysis Consulting
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.